配置实例
本节主要介绍常用流程的配置示例。
普通流程
以请假申请流程为例,介绍如何创建一个最简单的审批流程。本实例中将主要介绍任务表单和任务按钮的使用。
- 在下面的流程图中,设置了请假申请、部门领导审批以及 HR 审批三个用户任务节点。
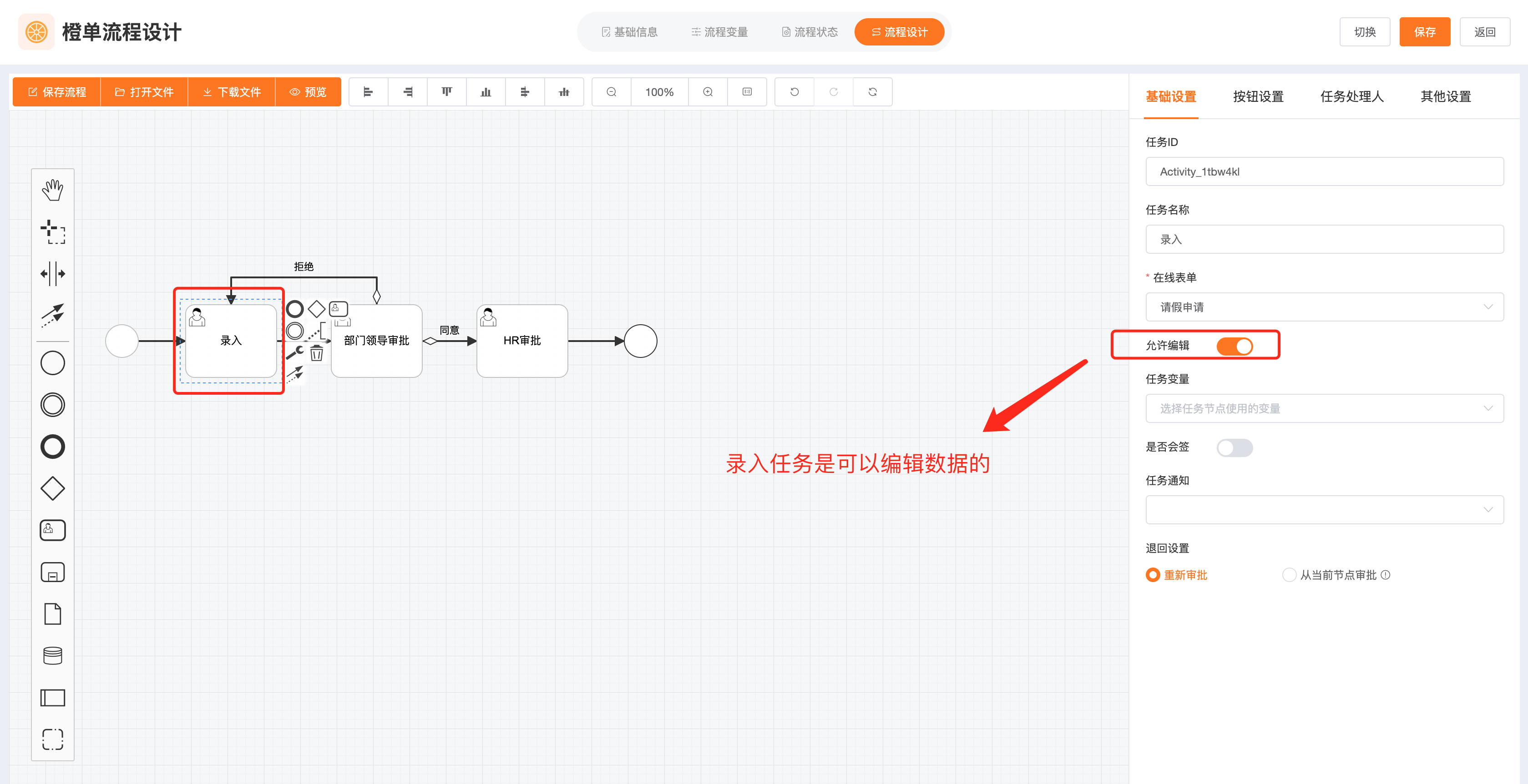
- 在该流程中,只有「请假申请」节点可以修改表单数据,因此将「请假申请」任务的「允许编辑」标记设置为选中。
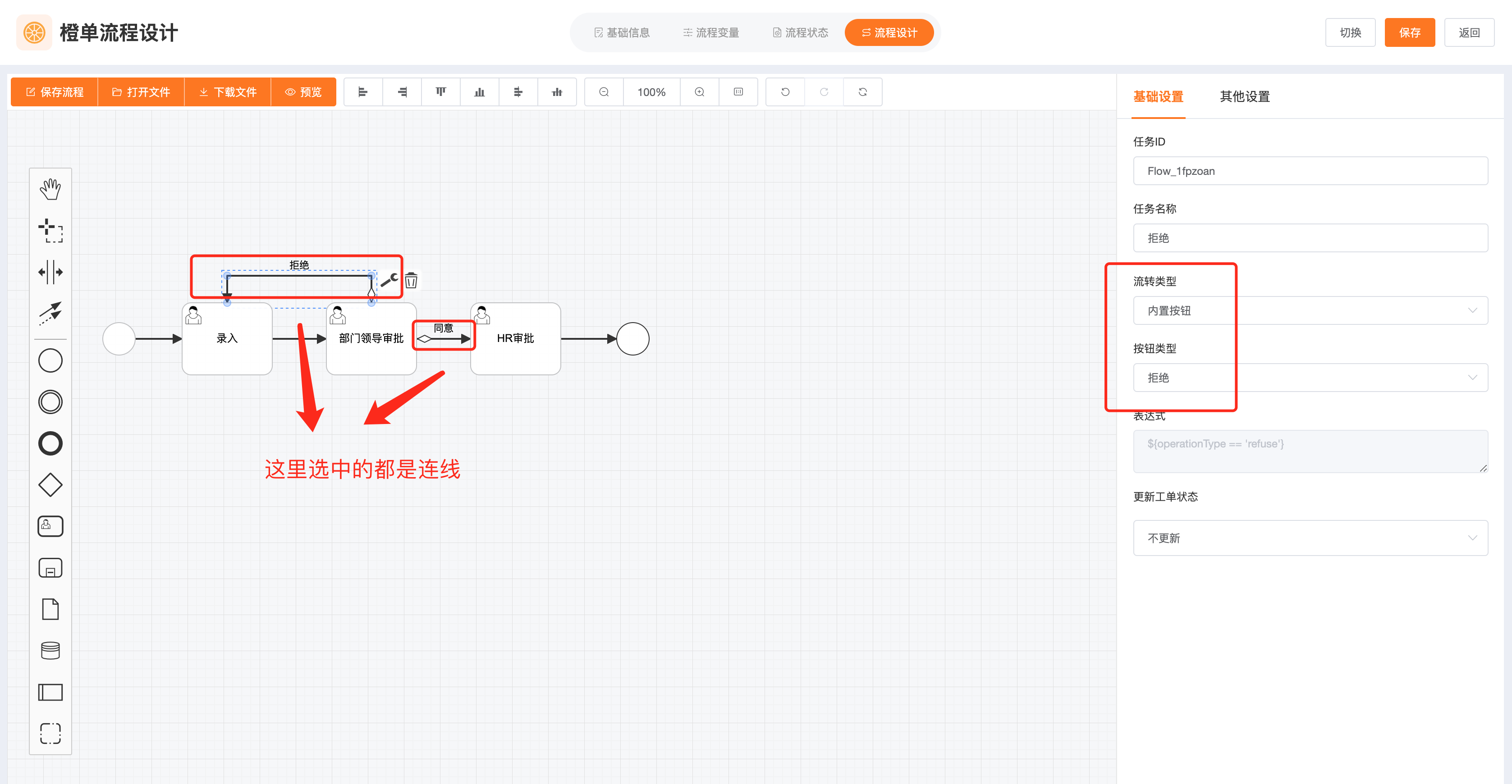
- 「部门领导审批」和「HR 审批」节点都需要「同意」和「拒绝」两个按钮,所以要在这两个节点下添加相应的按钮。

- 可以为不同的连线设置不同的按钮,当按钮被点击时,可以根据下图的配置,走不同的流转路径。
条件分支
本示例中的变量设置操作,仅适用于在线表单工作流,路由表单工作流的变量设置,会在后面的例子中给出。这里仍然以报销申请流程为例,介绍如何在流程中创建流程变量,并且使用流程变量作为条件流转的条件。
- 在流程变量设置步骤,添加流程变量,并将变量绑定到数据表字段。

- 为用户任务设置流程变量,只能选择上一步添加到流程中的变量。

- 在分支中选择「条件流转」并设置流转条件,如下图所示。
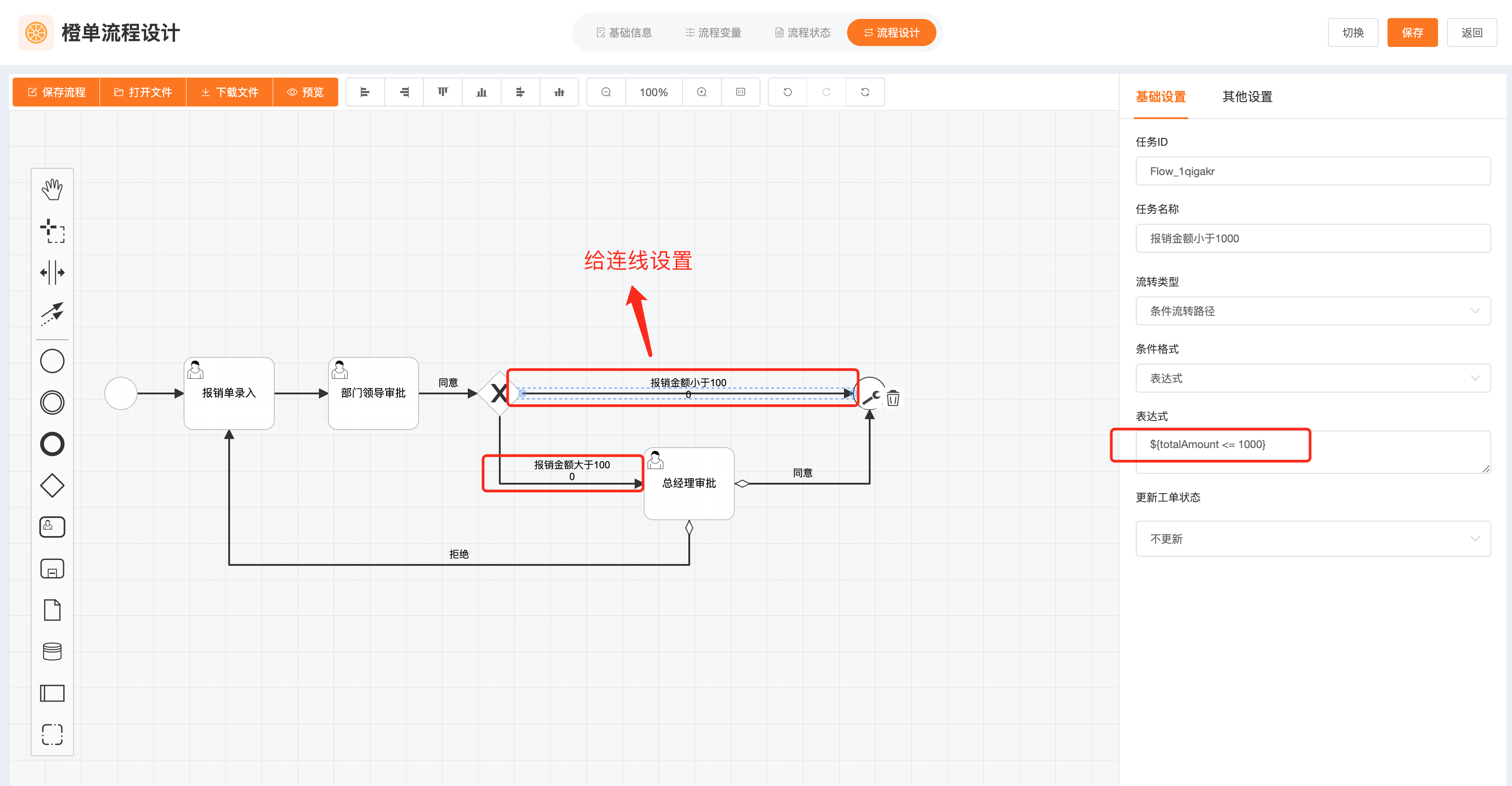
动态指定并行会签加减签
动态指定会签人是指在流程运行时,可以由会签发起人动态指派会签人,具体操作可见以下配置示例。
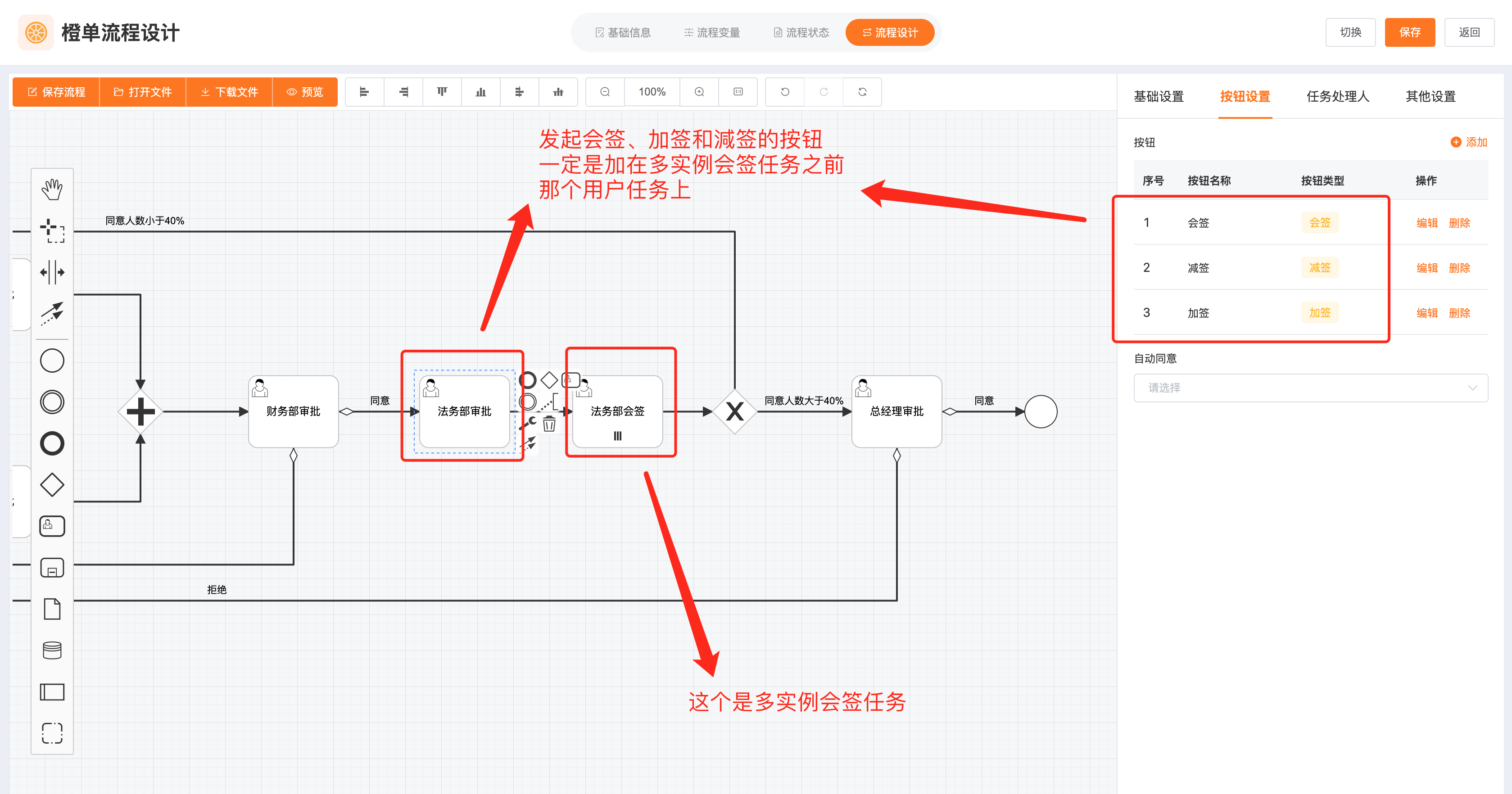
- 会签任务一定要配置为并行多实例任务,同时一定要在多实例会签任务的上一个用户任务节点添加「会签、加签和减签」按钮。
- 多实例任务内置变量。下图红框圈住的是流程引擎自带的内置变量,

- 上图中没有被红框圈住的变量,属于橙单自定义的多实例会签任务变量,具体功能见如下表格。
| 变量名 | 功能描述 |
|---|---|
| assigneeList | 多实例集合列表。 |
| multiNumOfInstances | 实例数量 (用于多实例任务节分支中判断) |
| multiAgreeCount | 同意实例数量,点击「同意 (会签)」类型的按钮触发。 |
| multiRefuseCount | 拒绝实例数量,点击「拒绝 (会签)」类型的按钮触发。 |
| multiAbstainCount | 弃权实例数量,点击「弃权 (会签)」类型的按钮触发。 |
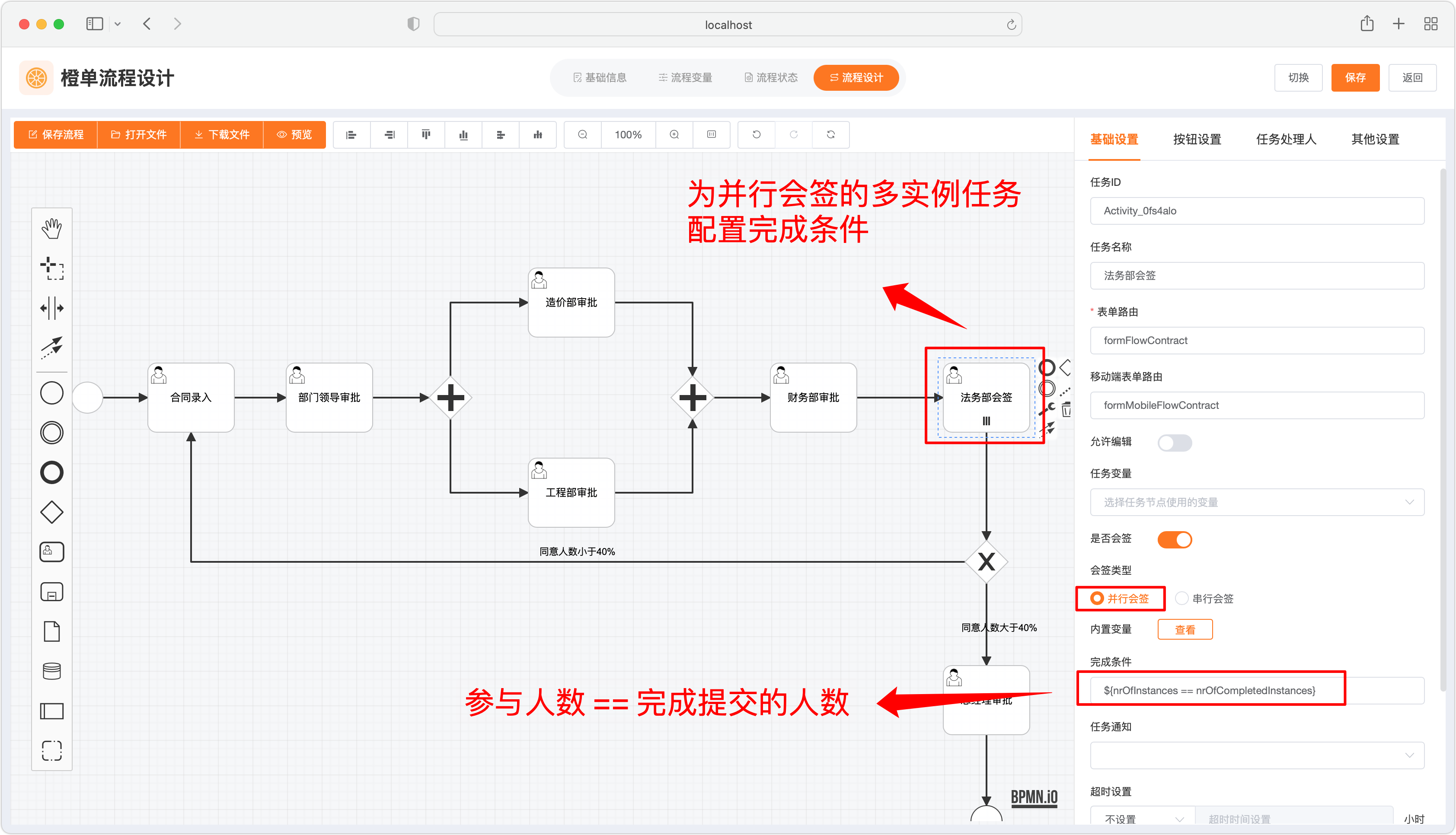
- 为多实例会签任务设置「完成条件」。在下图中,是要求所有会签候选人全部提交后才会结束当前会签任务。当然也可以设置百分比,如 ${nrOfCompletedInstances / nrOfInstances > 0.8},表示有 80% 的会签用户提交审批后,即可结束当前的会签任务。
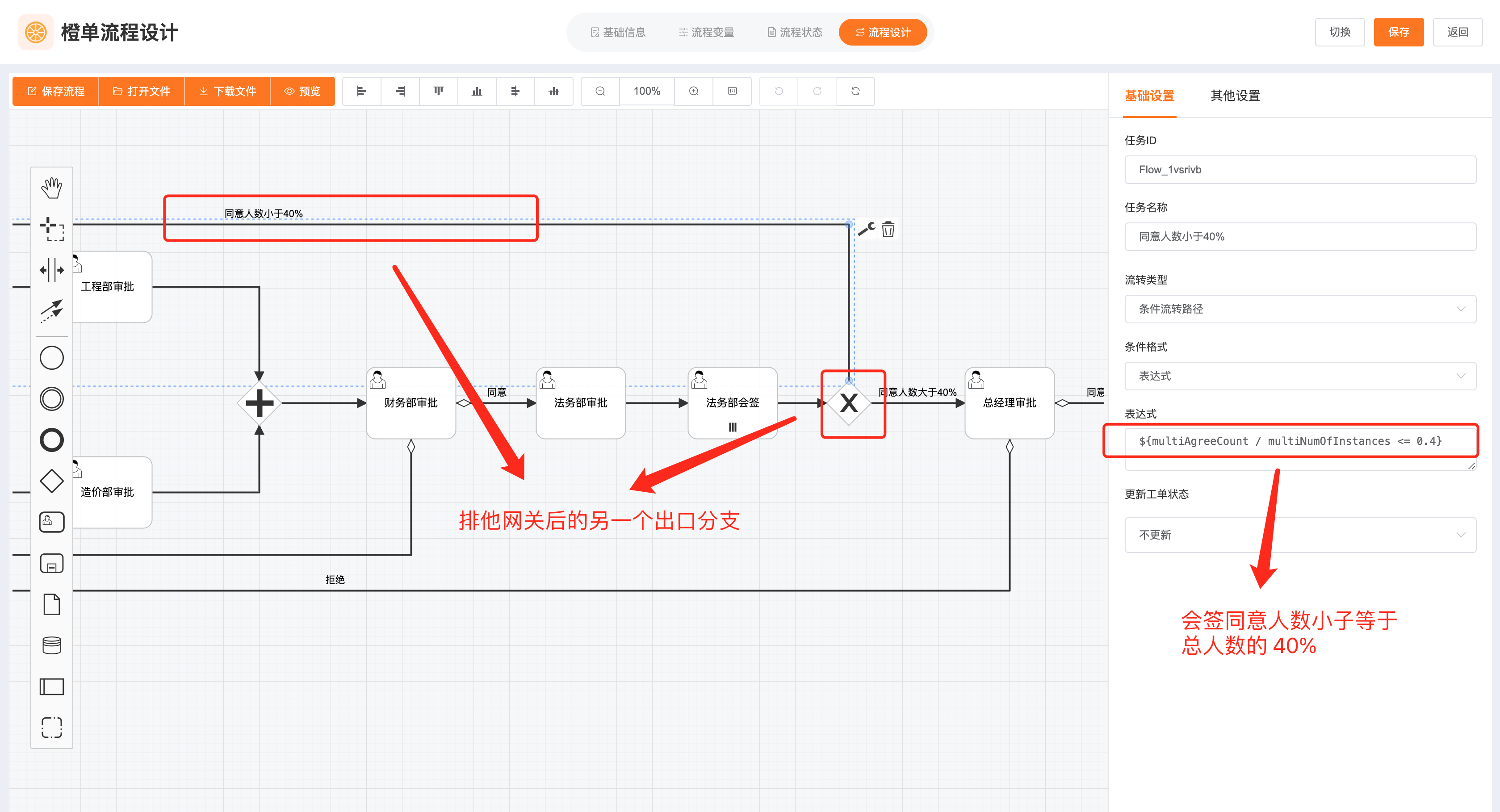
- 根据会签任务的审批结果,设置下一个任务的审批流转分支。在下图中,我们可以看到「排他网关」后面的流程分支连线,每个连线都配置了「流转条件」表达式,表达式中使用了我们为会签内置的多个自定义变量,仅当表达式设置的条件满足时,才会走当前分支。

- 多实例加签和减签。这两个按钮都是配置在「多实例会签任务」的上一个用户任务节点。加签的业务场景是,当会签的发起人发现需要更多的用户参与会签时,就可以在会签尚未结束时,添加新的用户。减签则反之,同样是会签的发起用户发现正在参与会签的某一用户,是不需要参与会签的,或是之前「手抖」误选进来的,此时就可以在会签尚未结束时,执行减签操作,移除其中的一到多个会签用户。

流程图设定并行会签人
- 与上一小节「动态指定并行会签加减签」最重要的区别是,会签人是在流程图中设置的,因此无需配置专门的会签发起任务,同时也不在支持「加减签」功能,其余逻辑和上一小节相同。
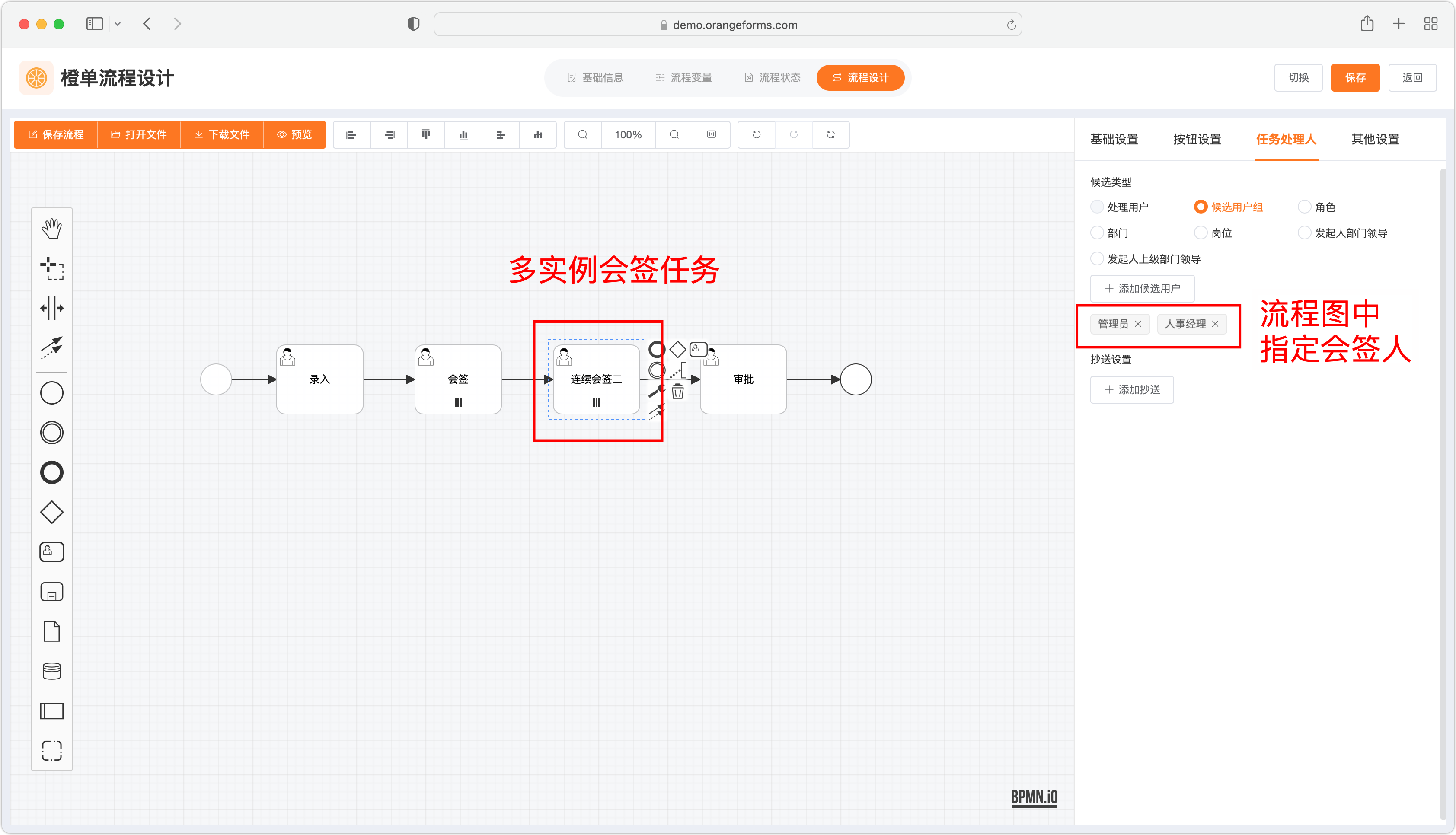
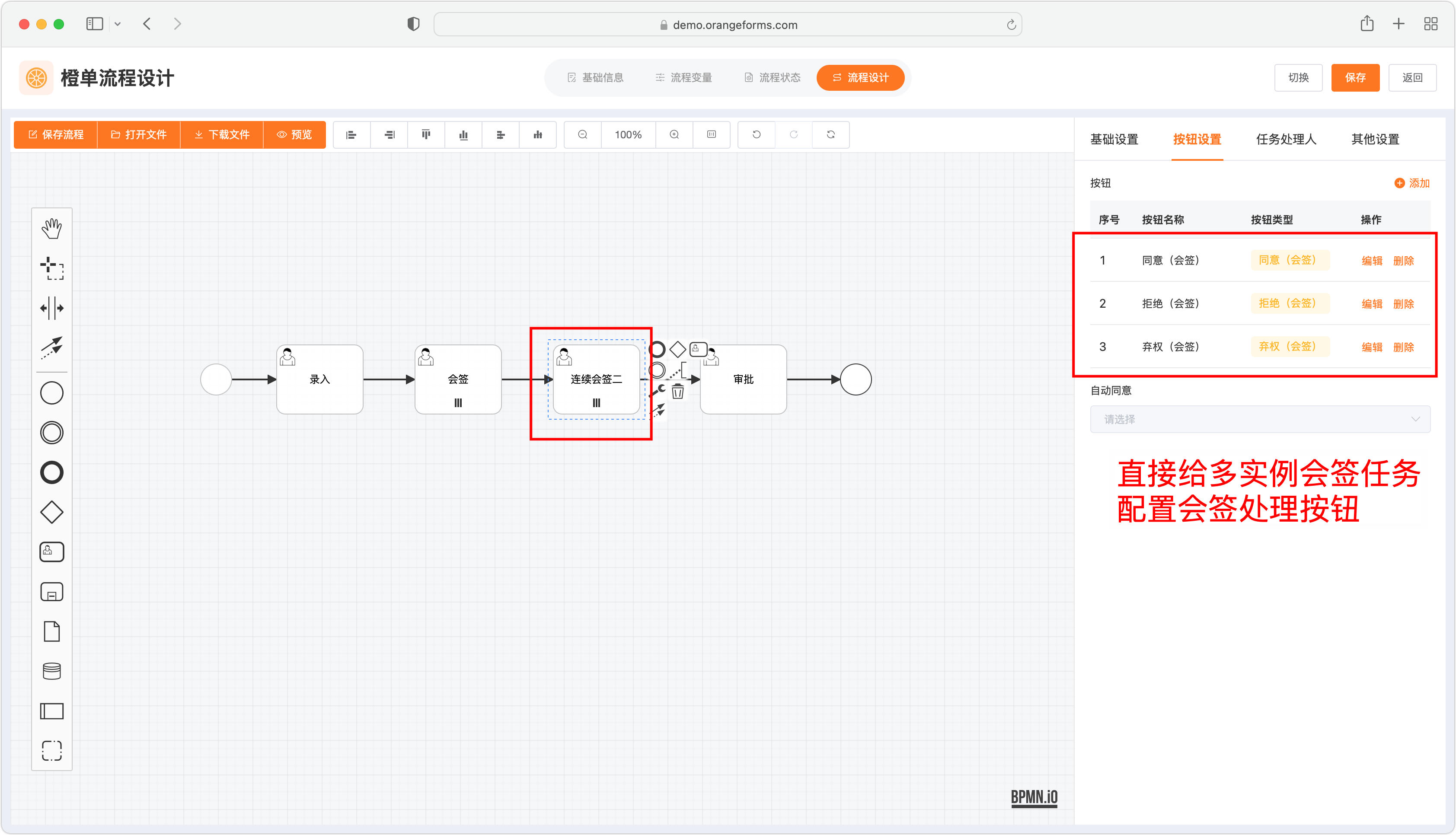
- 对于多实例会签任务,直接配置如下图所示的会签审批按钮即可。
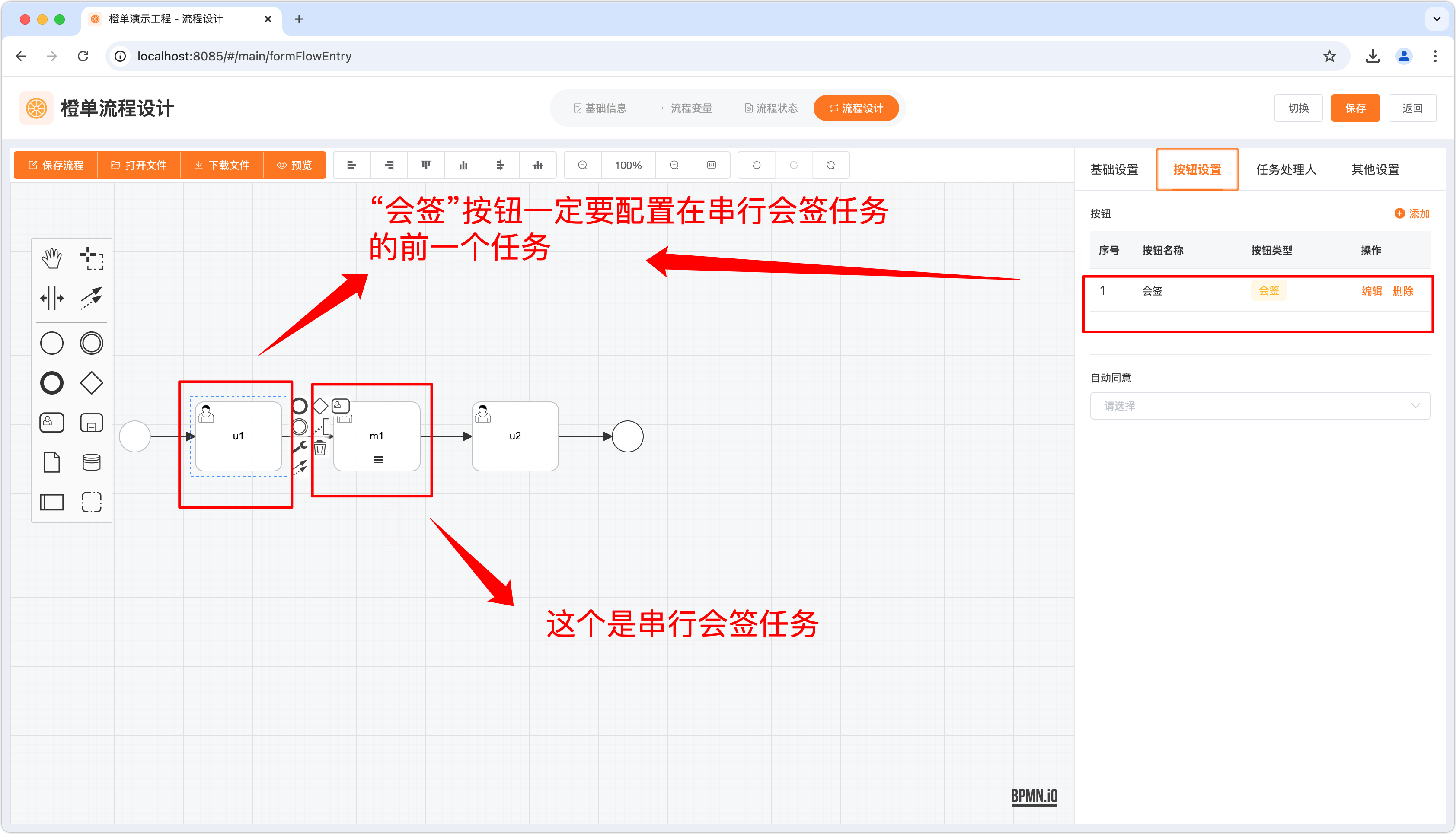
串行会签和前后加签
通过该实例介绍如何配置多人会签的多实例任务。
- 会签任务一定要配置为串行多实例任务,同时一定要在多实例会签任务的上一个用户任务节点添加「会签」按钮。
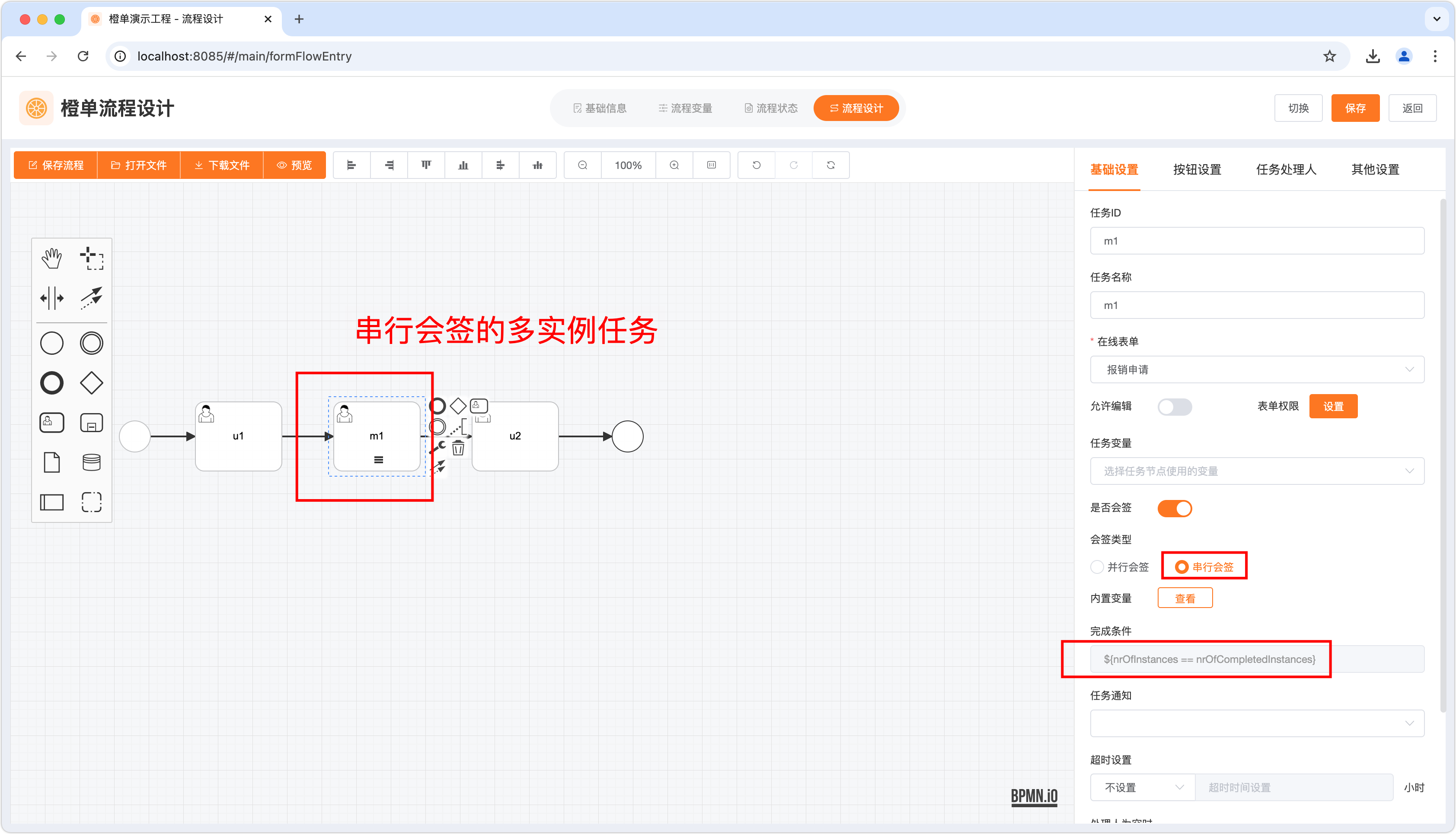
- 串行多实例会签任务的「完成条件」目前只能为 ${nrOfCompletedInstances == nrOfInstances},既全部会签人完成会签。
- 与并行会签不同,一定要在串行多实例会签任务节点添加「前后加签」按钮。

- 在执行串行会签任务时,如果选择「前加签」操作,当前的审批人将改为加签的第一个用户。
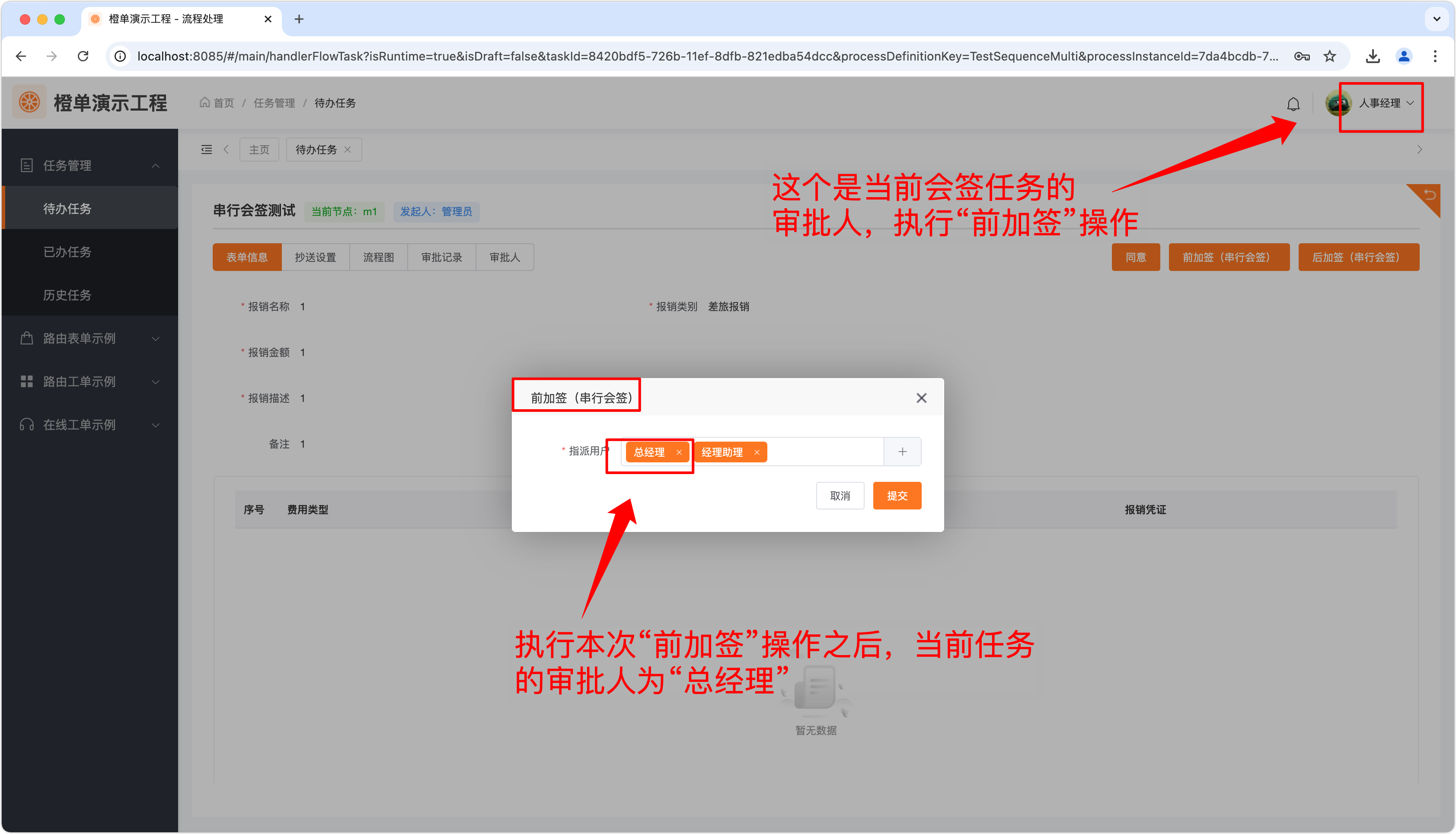
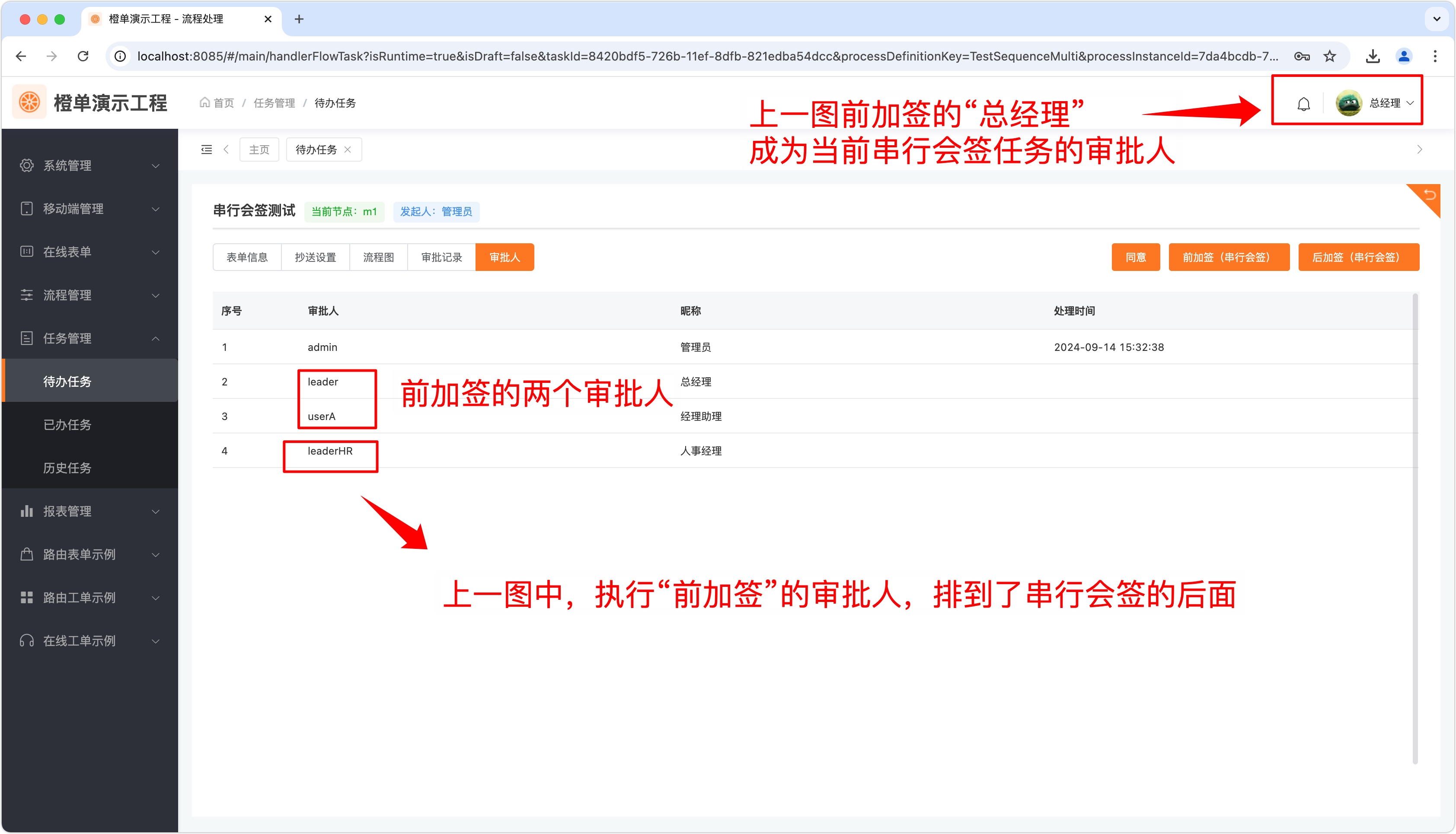
- 在上一步执行完串行会签任务的「前加签」操作后,执行该操作的审批人将排到串行会签任务的加签人之后。如下图所示的「leaderHR」的审批顺序已经排到了前加签审批人「leader 和 userA」之后。
流程任务动态指定审批人
在流程编辑器中,在当前用户任务中为下一个审批任务动态设置审批人,具体操作步骤如下。
- 在用户任务配置「指定审批人」操作。如下图所示,为指定任务配置「指定审批人」,运行到该任务时,可通过点击这里配置「指定审批人」操作按钮,为下一个任务动态指定一或多个审批人,注意,在运行时最终只能选择审批用户或逗号分隔的用户组,我们会在本小节后面的截图中给出与下图匹配的运行时场景。

- 为下一个任务配置审批人,需要说明的是,下一个任务的审批人必须是「指定审批人」变量。
这里需要重点说明的是,如果同时指派多个候选人,下面的候选类型选择「候选用户组」。

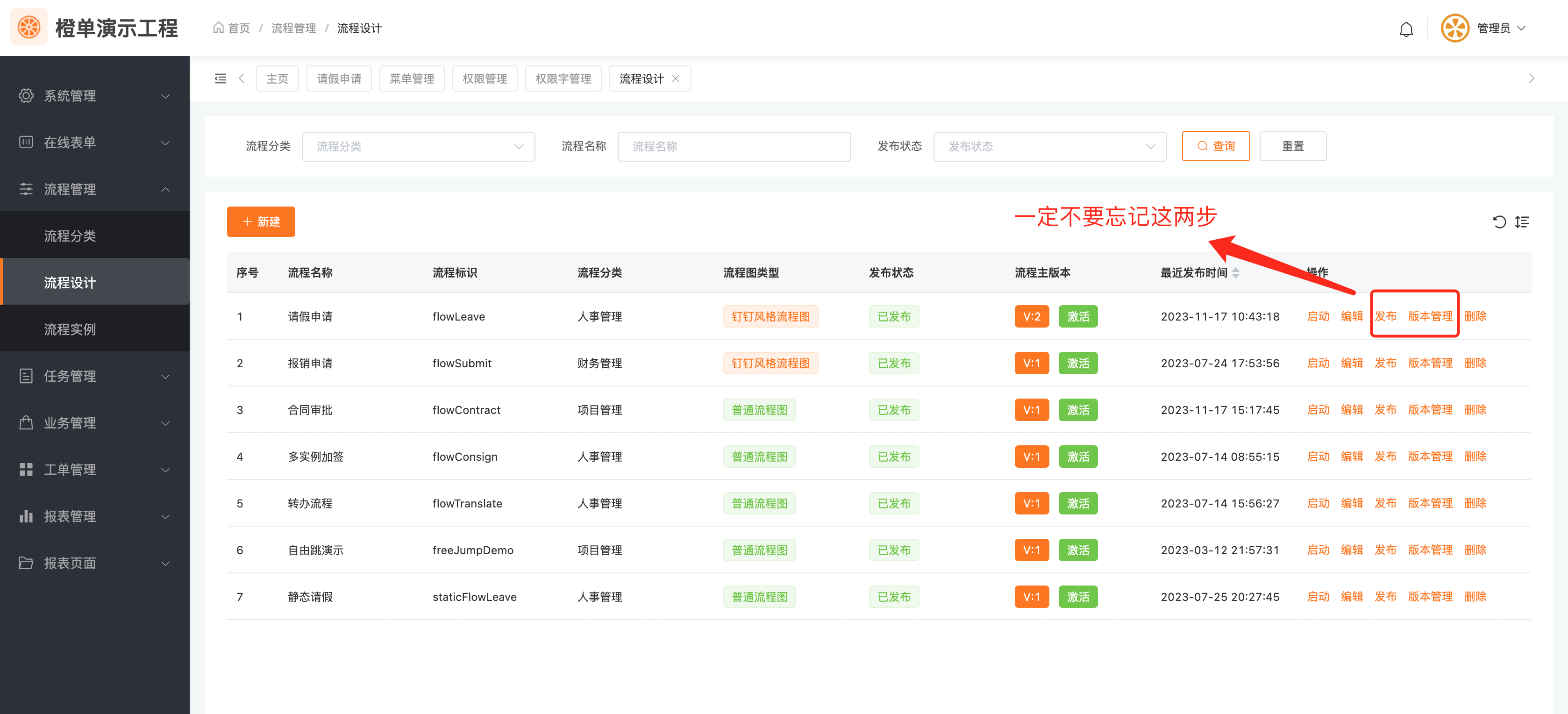
- 流程保存之后,发布并设置为主版本。

- 启动流程并运行到配置了「指定审批人」操作的用户任务。这一步会选择用户或用户组,多个用户之间逗号分隔。这里选择的用户或者用户组,将成为下一个审批任务的审批候选者。



- 如果上图所示,以「人事经理」用户身份登录,在待办任务列表中,就会看到该条审批记录。

流程变量指定审批人
在流程编辑器中,将用户任务的审批人配置为流程变量,变量值来自于绑定的业务表字段。这里需要注意的是,如果指定的是用户,而非用户组 (部门、角色和岗位等),切记要使用「用户登录名」字段,目前并不支持使用「userId」字段值作为绑定的变量值。
- 因为在后面的配置中,我们指定的是审批用户,而非用户组。因此这里配置的流程变量,必须绑定到「用户登录名」字段。如果是审批用户组,如部门、角色和岗位等,则可以指定 deptId、roleId 和 deptPostId 等字段。
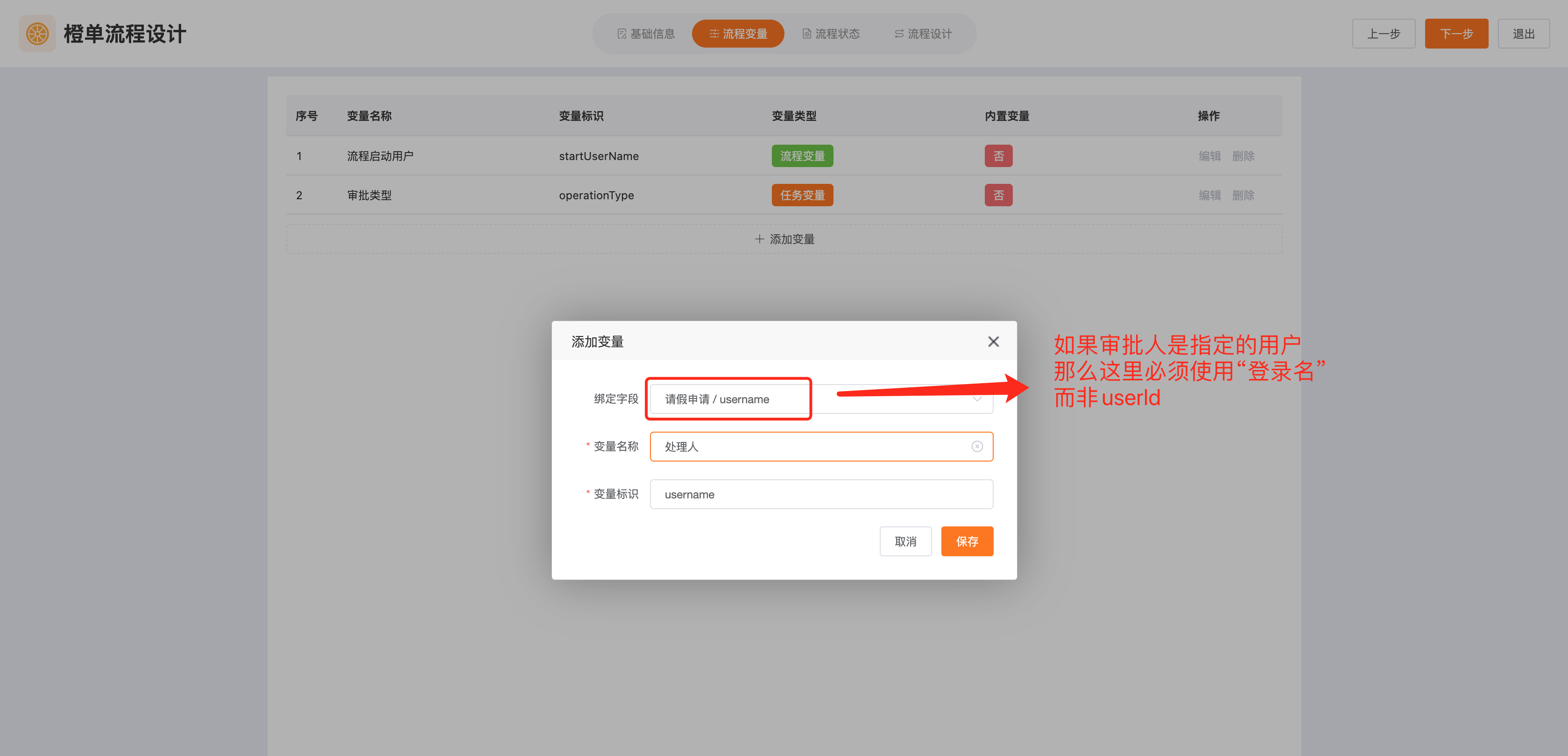
- 在流程编辑中,为指定审批人任务的上一个任务绑定「处理人」变量。

- 在流程编辑中,为用户任务指定「候选类型」。本例中我们选择的是「处理用户」。
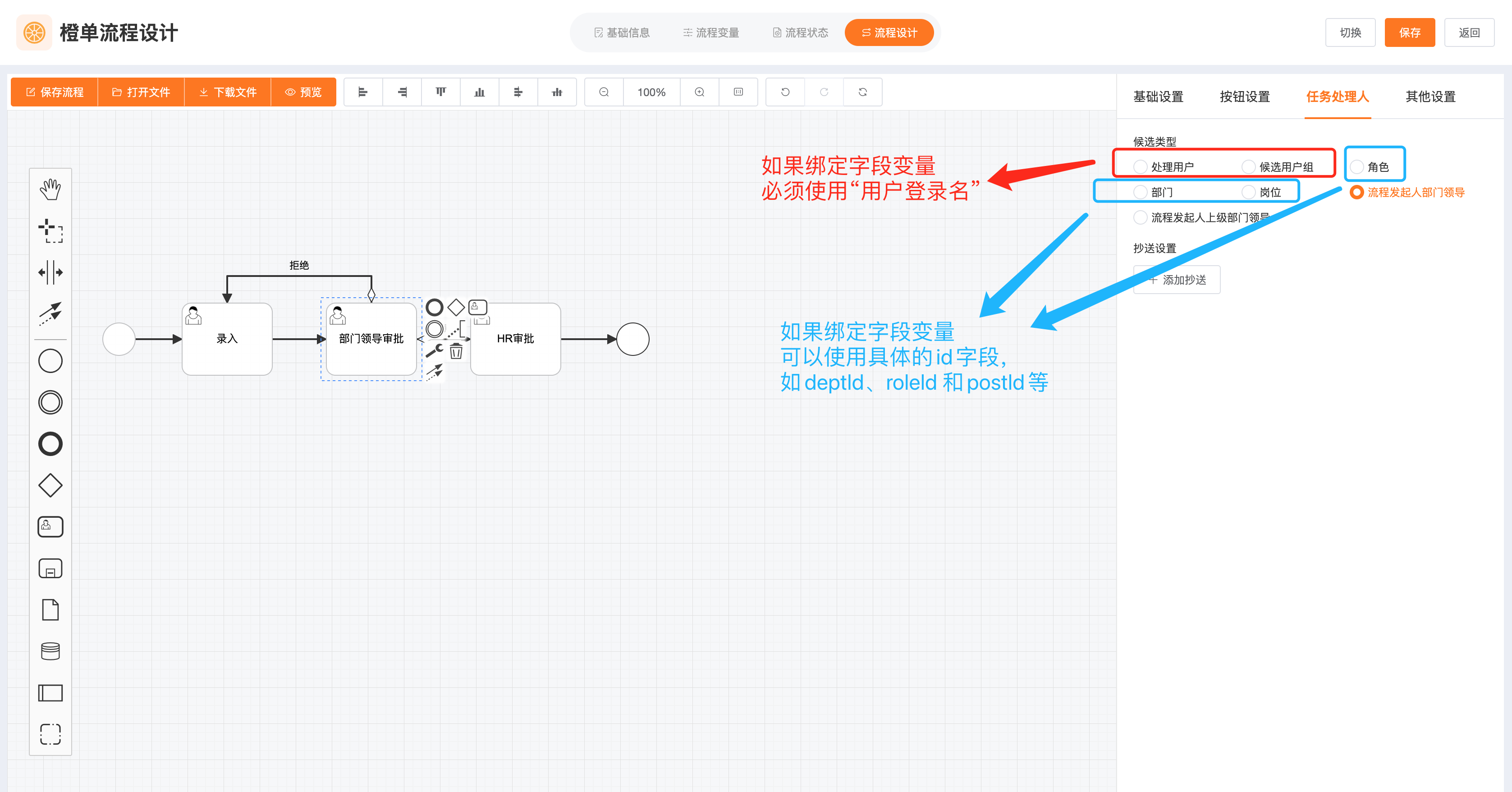
- 在「选择用户」的弹框中,直接输入变量名,然后点击「添加用户」即可。
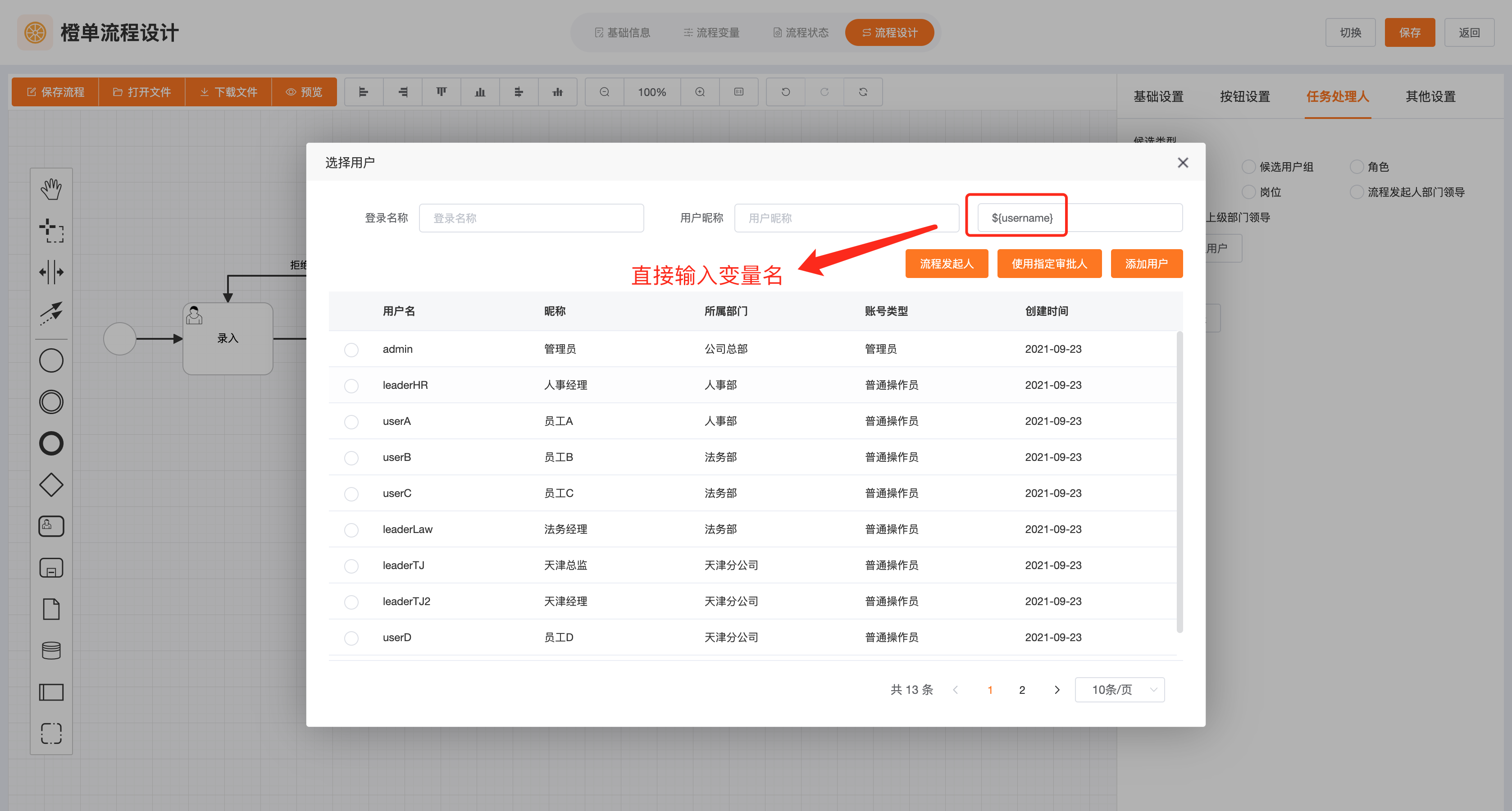
- 保存流程后,发布流程,并将其设置为主版本。
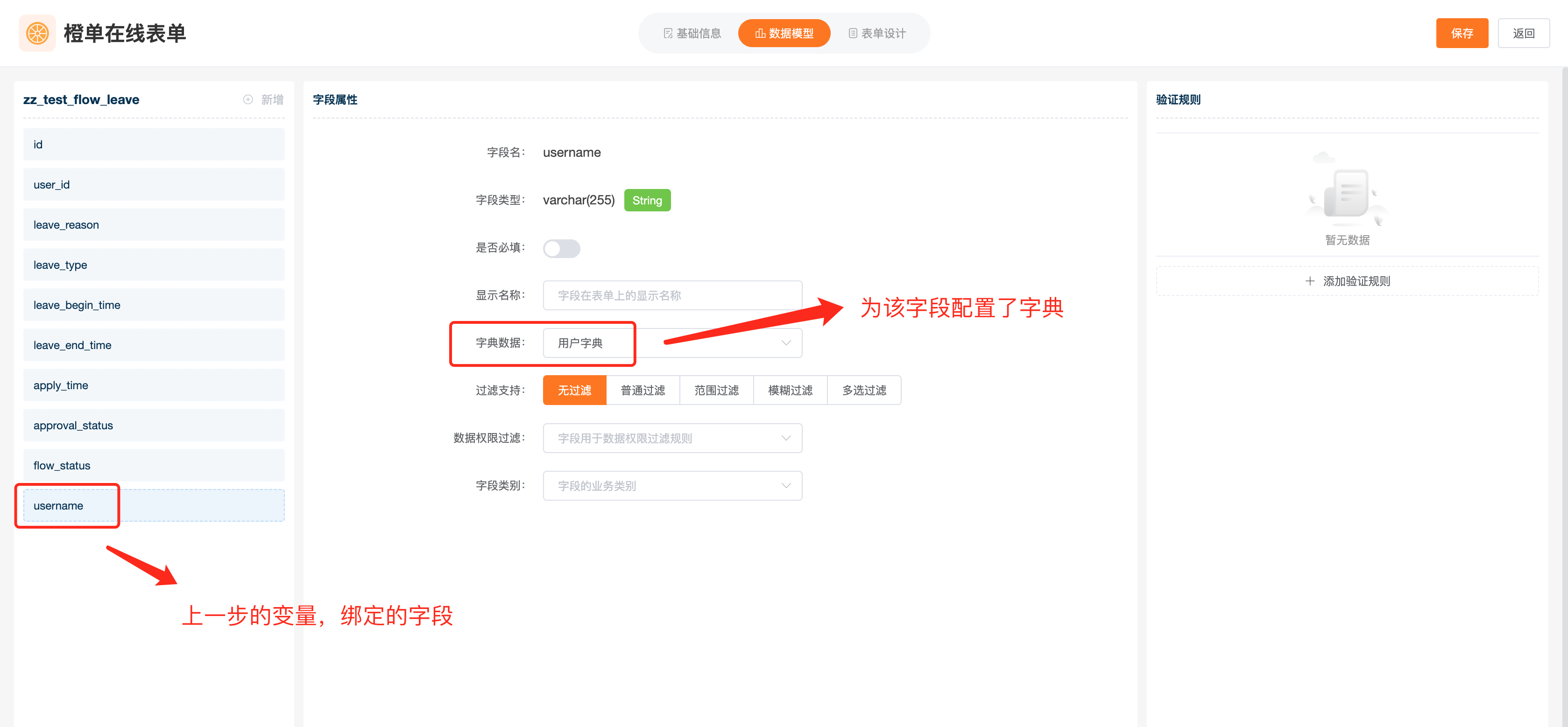
- 配置在线表单的页面组件,以便可以在流程录入页面选择「处理人」。在下图中,我们需要现为「username」字段设置字典,这样「处理人」字段所关联的下拉框组件,就可以显示用户列表了。下图中的「用户字典」字典的字典键必须为「loginName」,具体配置见下下张图。

- 将「处理人」字段与「下拉框」组件绑定。下拉框中的数据列表,为上一步配置的「用户字典」的字典数据列表。

- 启动流程,在录入业务数据时,为绑定字段「处理人」选择下一个任务的指定审批人。
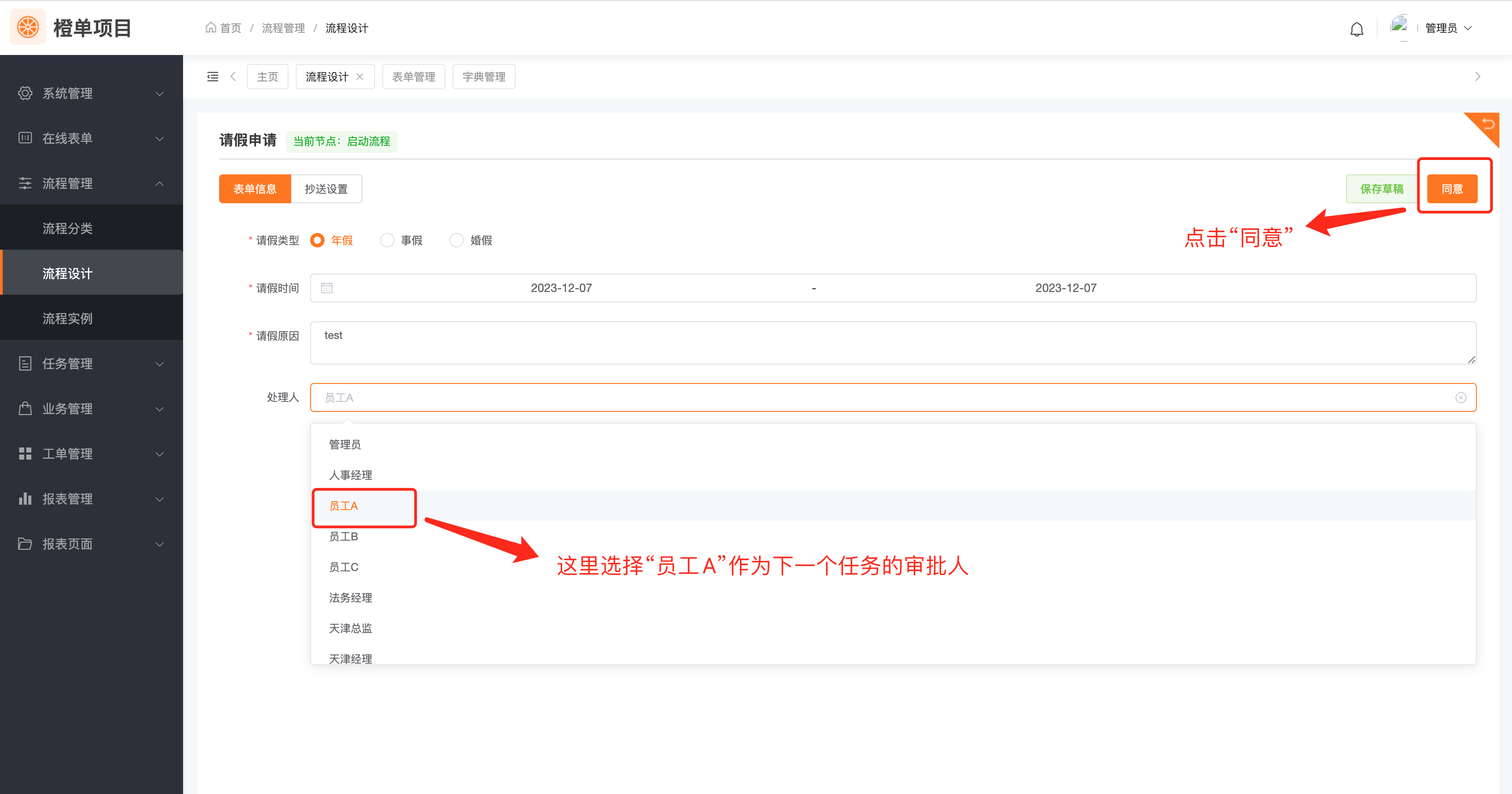
- 以上一步选择的「userA」身份登录,打开待办任务页面,可以看到「userA」已经是那个任务的待办用户了。

流程表达式设置审批人
在流程编辑器中,我们可以通过「EL 表达式」的方式,为指定任务设置审批人或审批用户组,具体配置如下图所示。
- 选择「变量表达式」作为用户或用户组的选择方式。

- 选择用户分组方式,同时在其右侧输入「EL 表达式」。由于 flowable 的 Spring Starter 做了很好的整合,因此这里直接输入 Spring Bean 的方法名即可。需要注意的是,末尾必须包含「圆括号」。

- EL 表达式方法的返回值是字符串类型,如果是用户组,需要返回用户的登录名,多个用户之间「逗号」分隔,如 admin,leaderHR,manger。如是其他分组形式,则需要返回相对应的 ID 集合,多个 ID 之间同样也是「逗号」分隔,如 1779777400603676672,1779777400603676675 等。

操作按钮指定流程分支
审批人点击不同的审批操作,可以选择不同的流程审批路径,具体配置方式如下。
- 在流程图中,可以配置多个表示「同意」审批类型的操作按钮,同时为每个操作添加变量,这里需要注意的是,尽量不要使用字段变量,变量名和变量值可以随便定义。



- 为当前流程任务的「输出连线」配置条件,这样当审批人选择不同操作按钮时,便可以选择不同的执行路径。


- 最后看一下实际的审批操作效果。

流程事件
橙单目前支持两种类型的事件配置,分别是流程实例和流程任务的事件。
流程事件配置
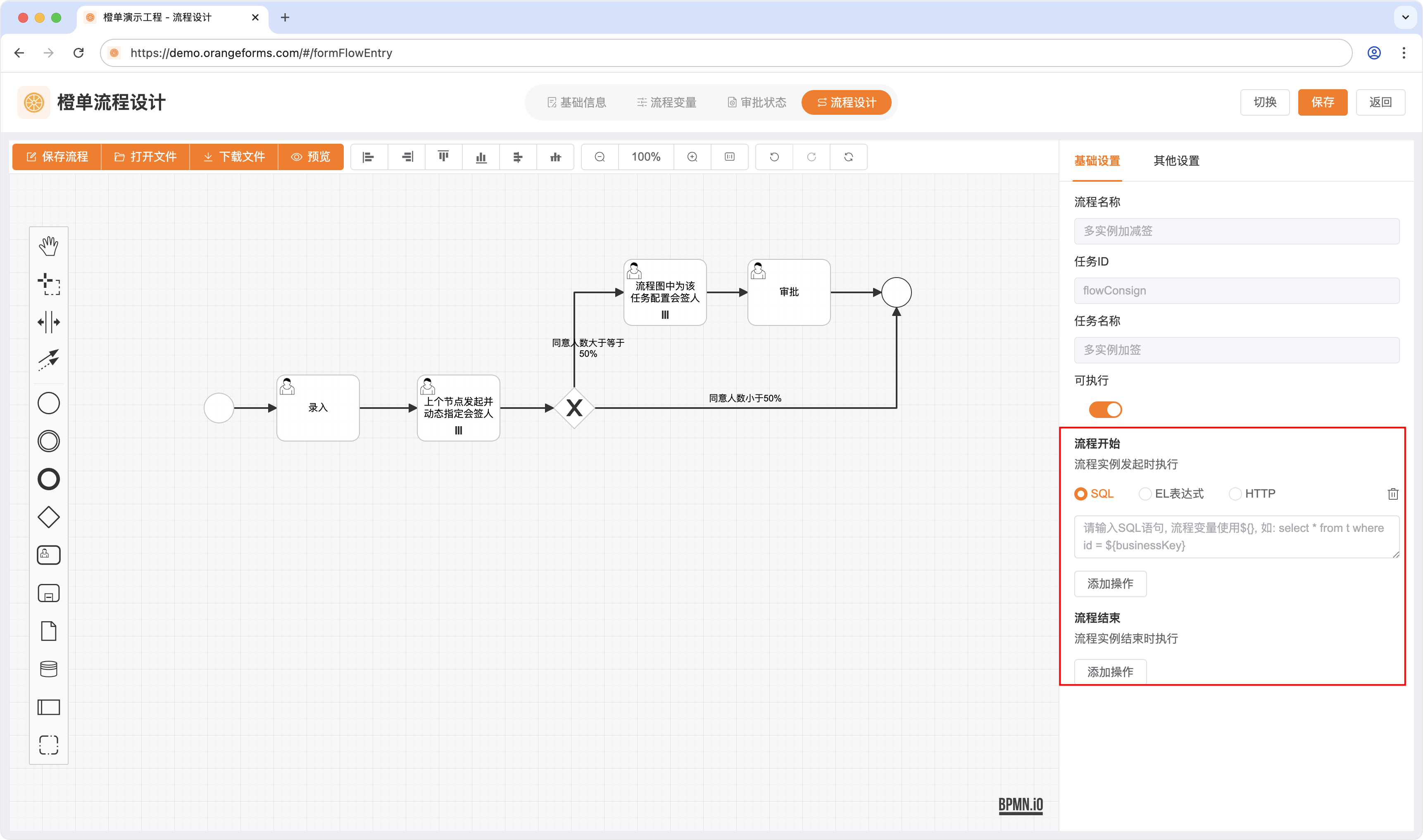
- 点击流程图空白处,在基础设置标签页即可看到「流程开始」和「流程结束」的事件配置,具体见下图。在流程发起或结束时,会执行这里配置的操作,可以同时配置多个。
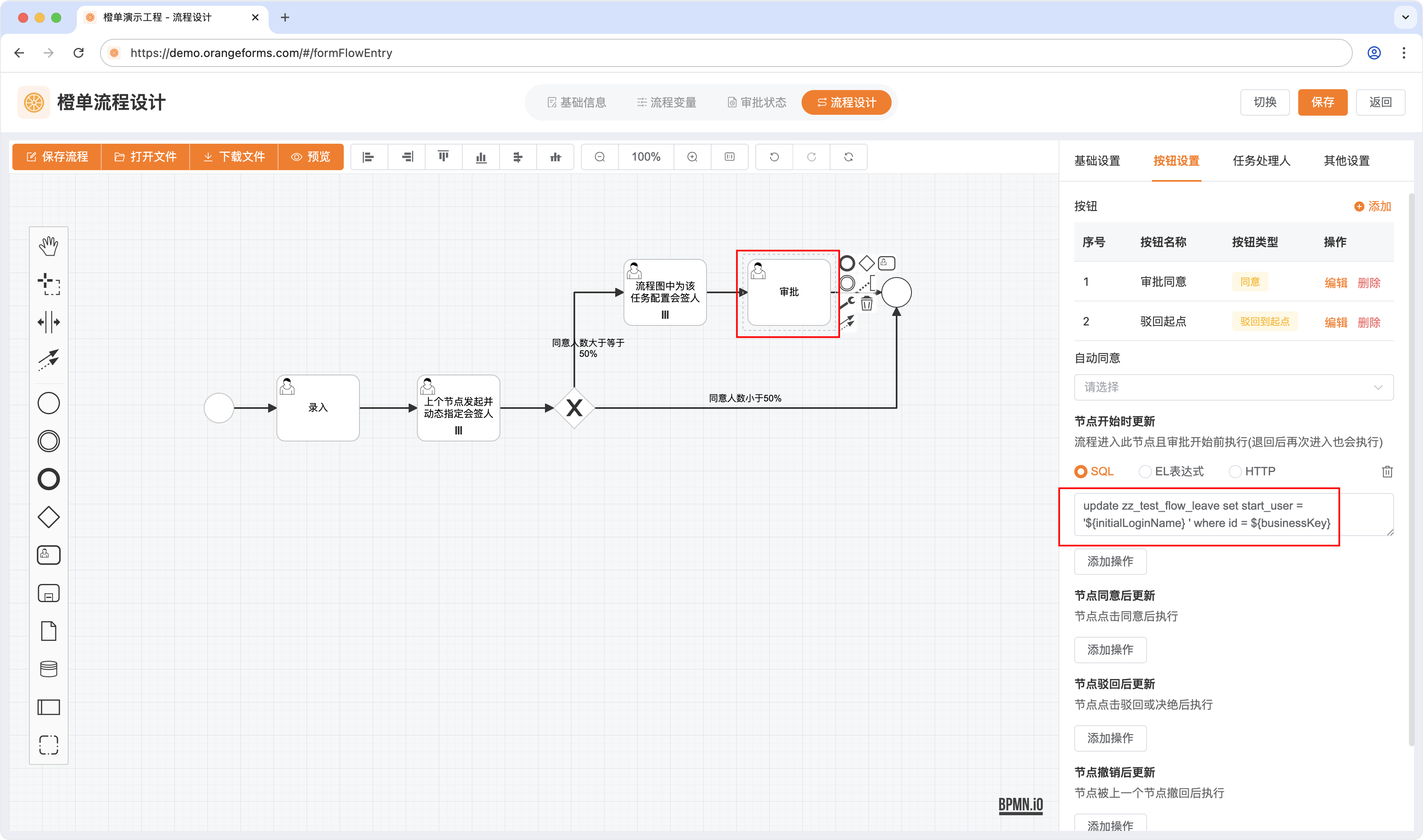
- 点击任意「流程任务」,在按钮设置标签页即可看到与任务相关的事件处理功能。相应的 SQL、EL表达式或 HTTP 接口调用等配置,会在流程任务相应事件被触发时执行,如下图所示,当「审批」任务点击同意按钮时,会执行此处配置的 SQL 语句。
注意事项
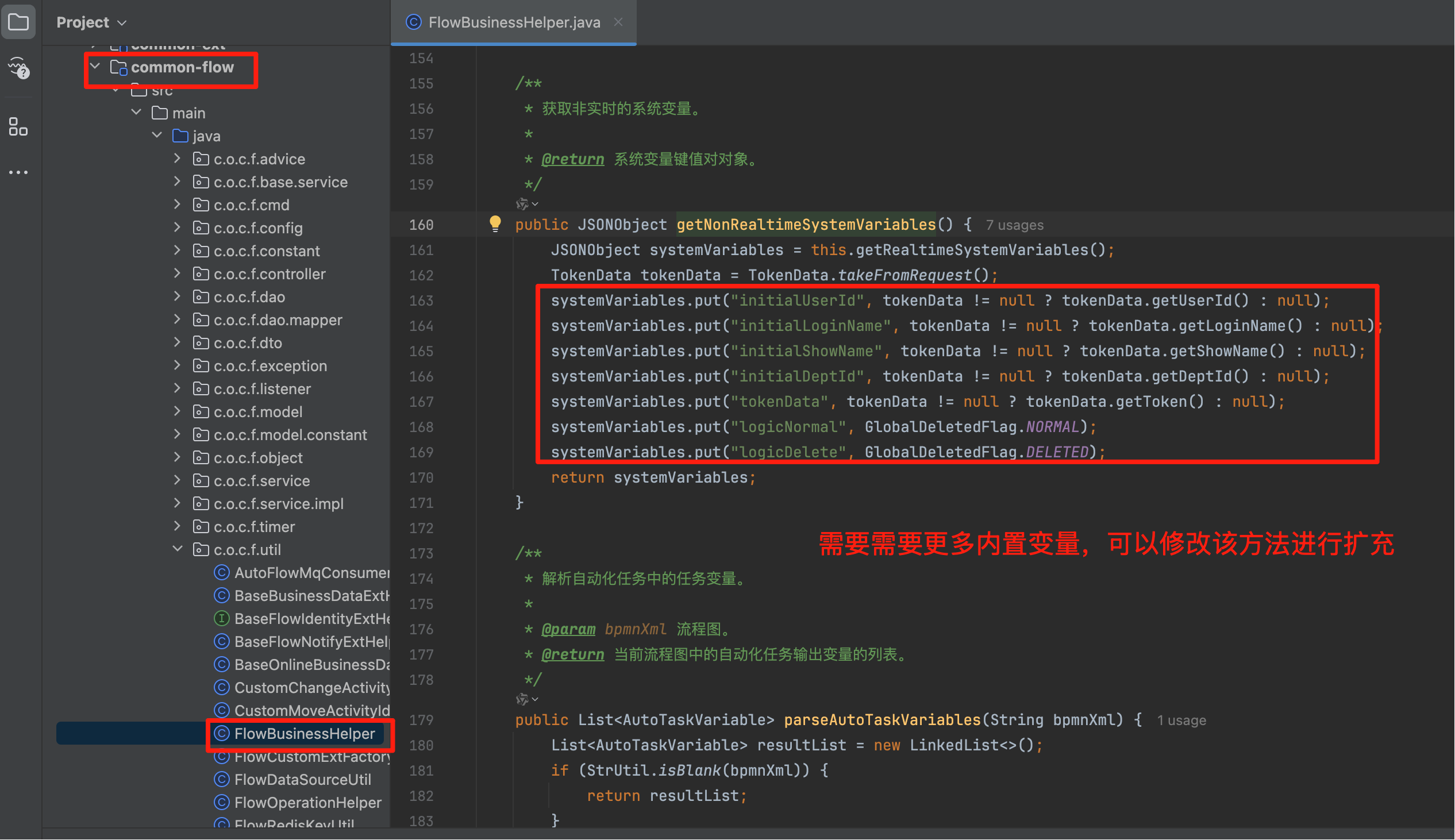
- 在 SQL、EL 表达式和 HTTP 接口中可以使用的变量如下图所示,请自己阅读下面截图中的文字注释。
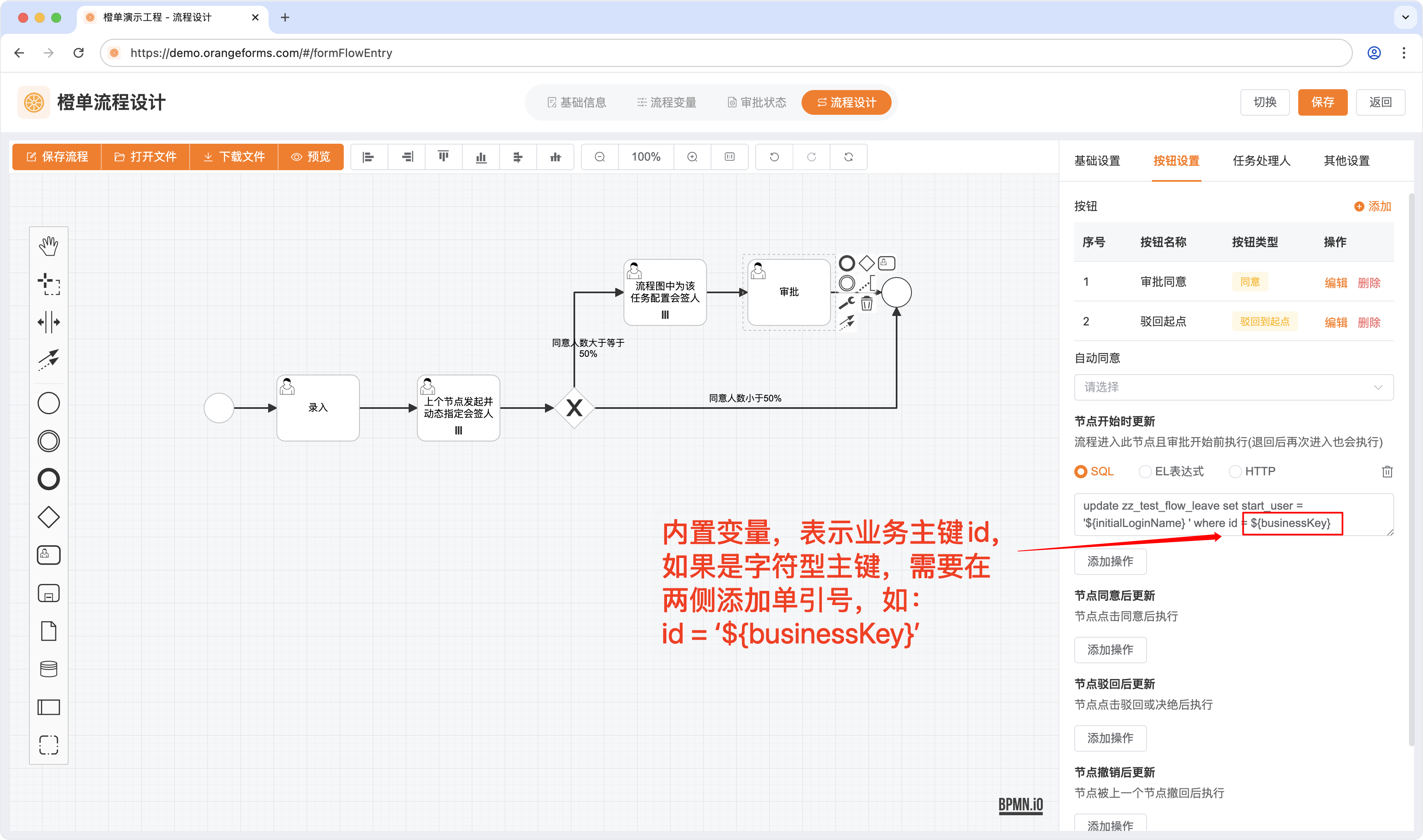
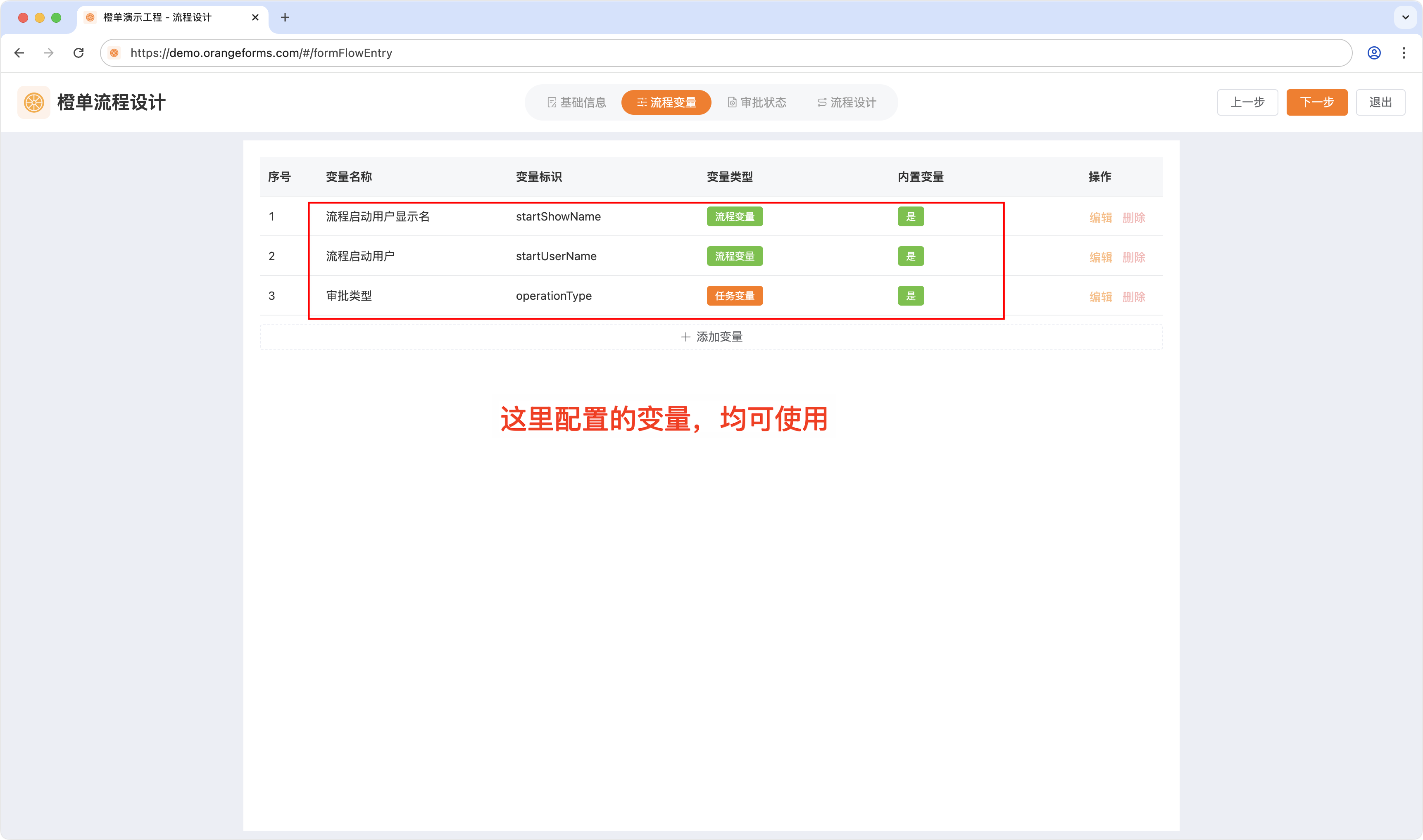
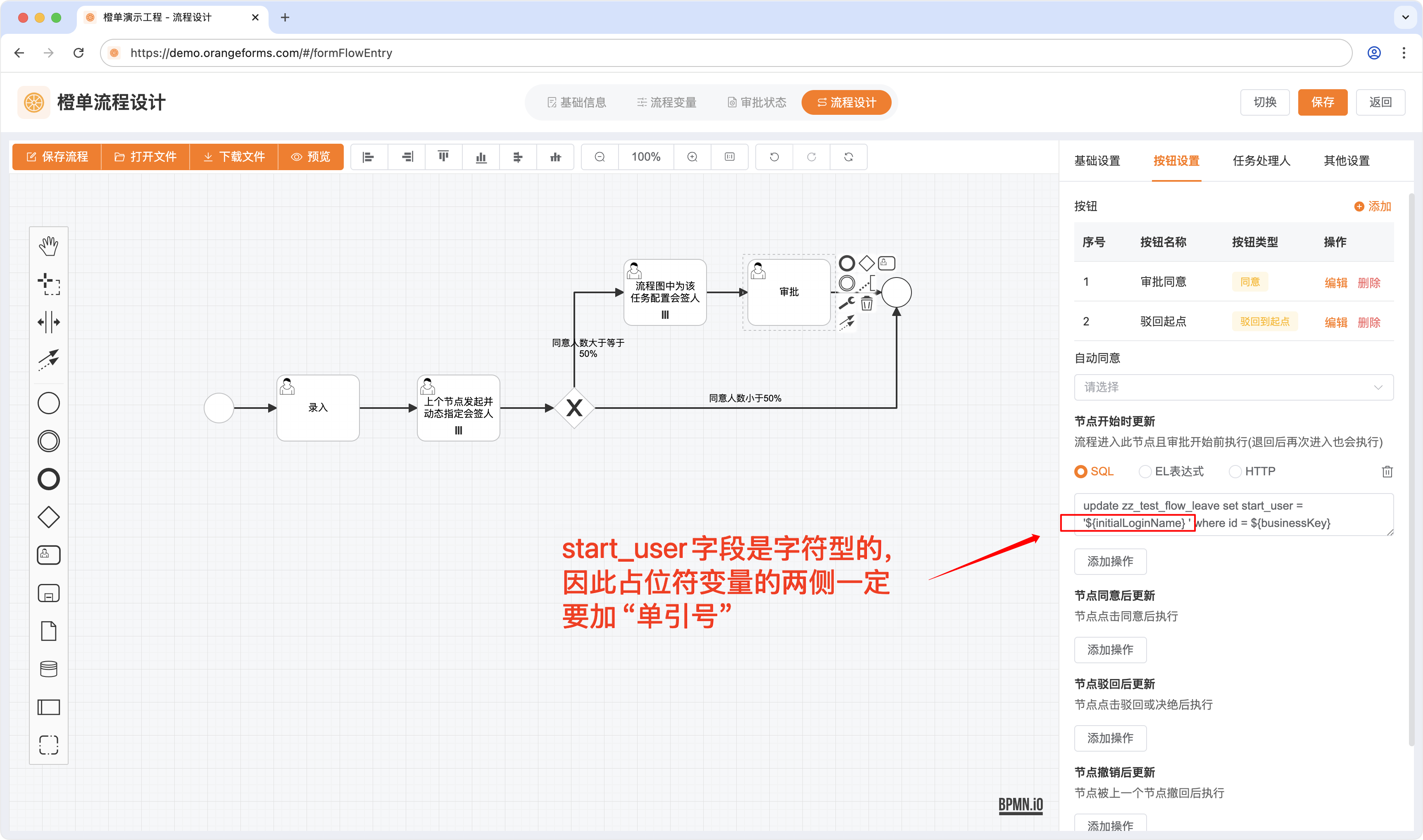
- SQL 语句的的变量仅为占位符,如果是字符型数据,需要在变量两侧添加「单引号」,具体见下图。
- EL 表达式的书写规则以及变量的使用方式,可参考本章的 流程表达式设置审批人小节,表达式中能够使用的变量,请参考本小节前面的内容。
代码实例
本小节主要介绍相关的代码示例。
发起人部门领导岗位
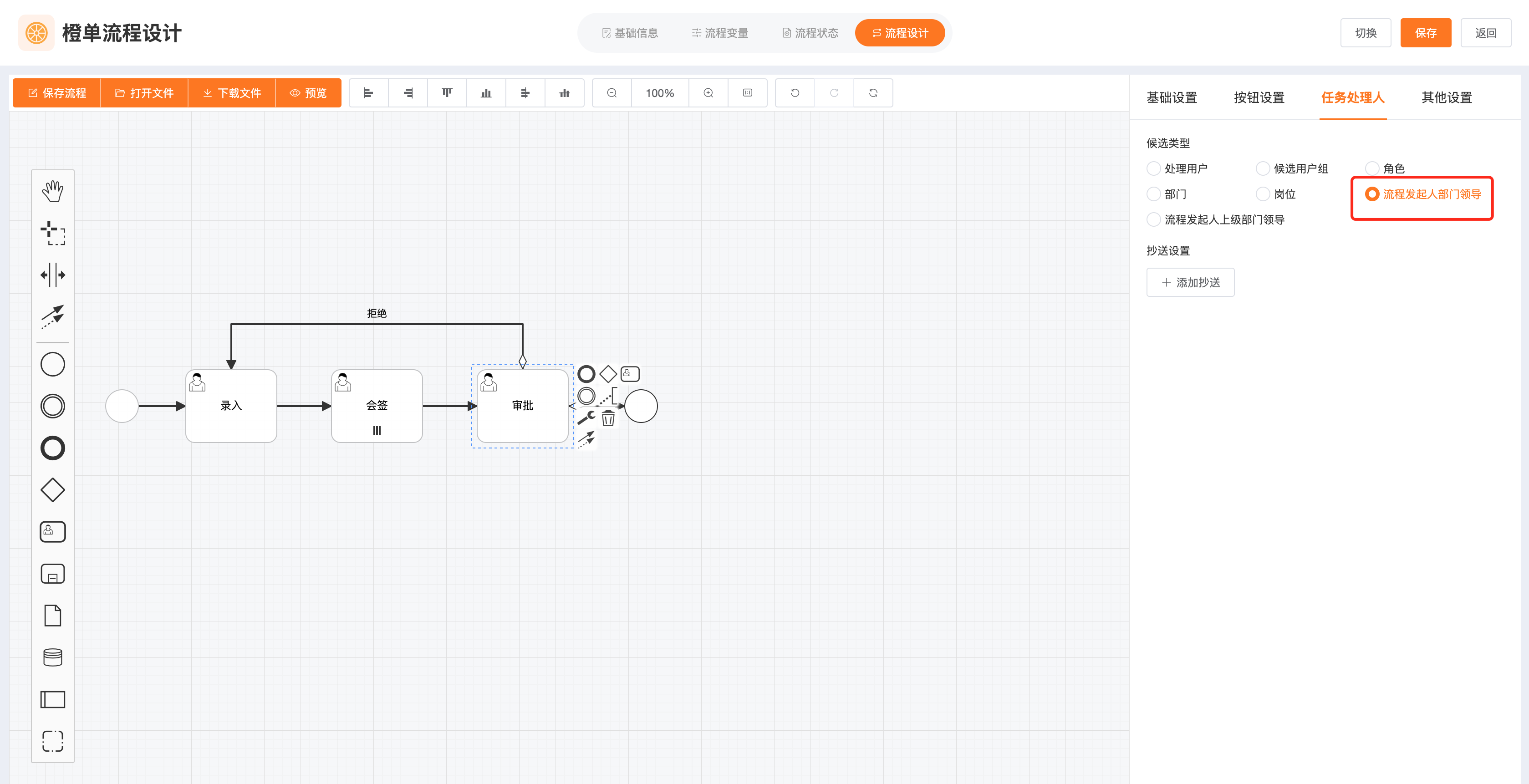
- 橙单目前已经支持「发起人本部门领导」和「发起人上级部门领导」,具体见下图。当前小节主要介绍后端相关的扩展代码。这样在缺省实现不满足需求的情况下,开发者可自行修改。
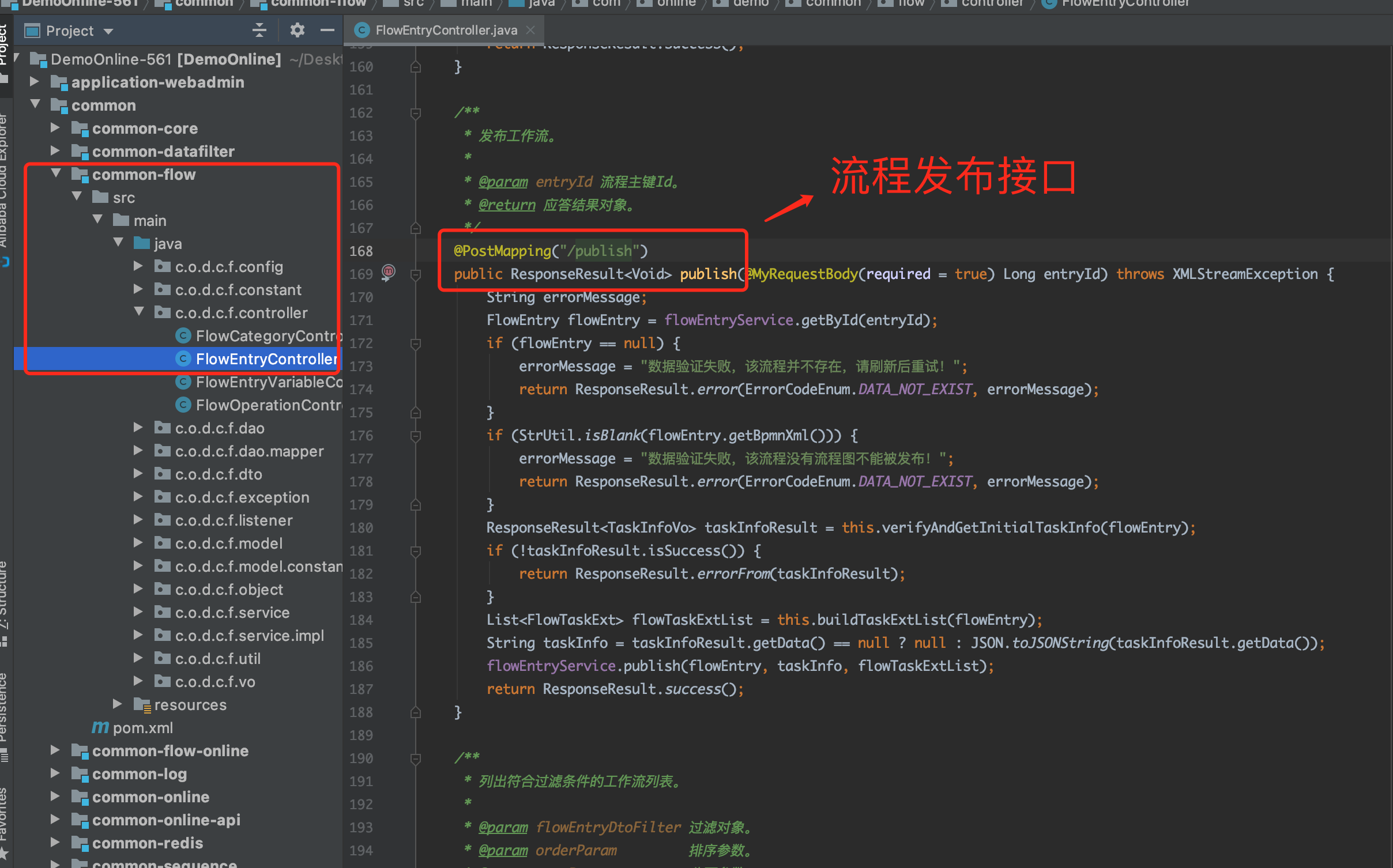
- 在调用流程发布接口发布流程的时候,如果流程定义中包含分组类型是「发起人部门领导岗位」和「发起人上级领导岗位」的用户任务时,我们会自动为这个用户任务绑定用户监听器,监听器的具体作用后面会讲述。见下图及文字注释。

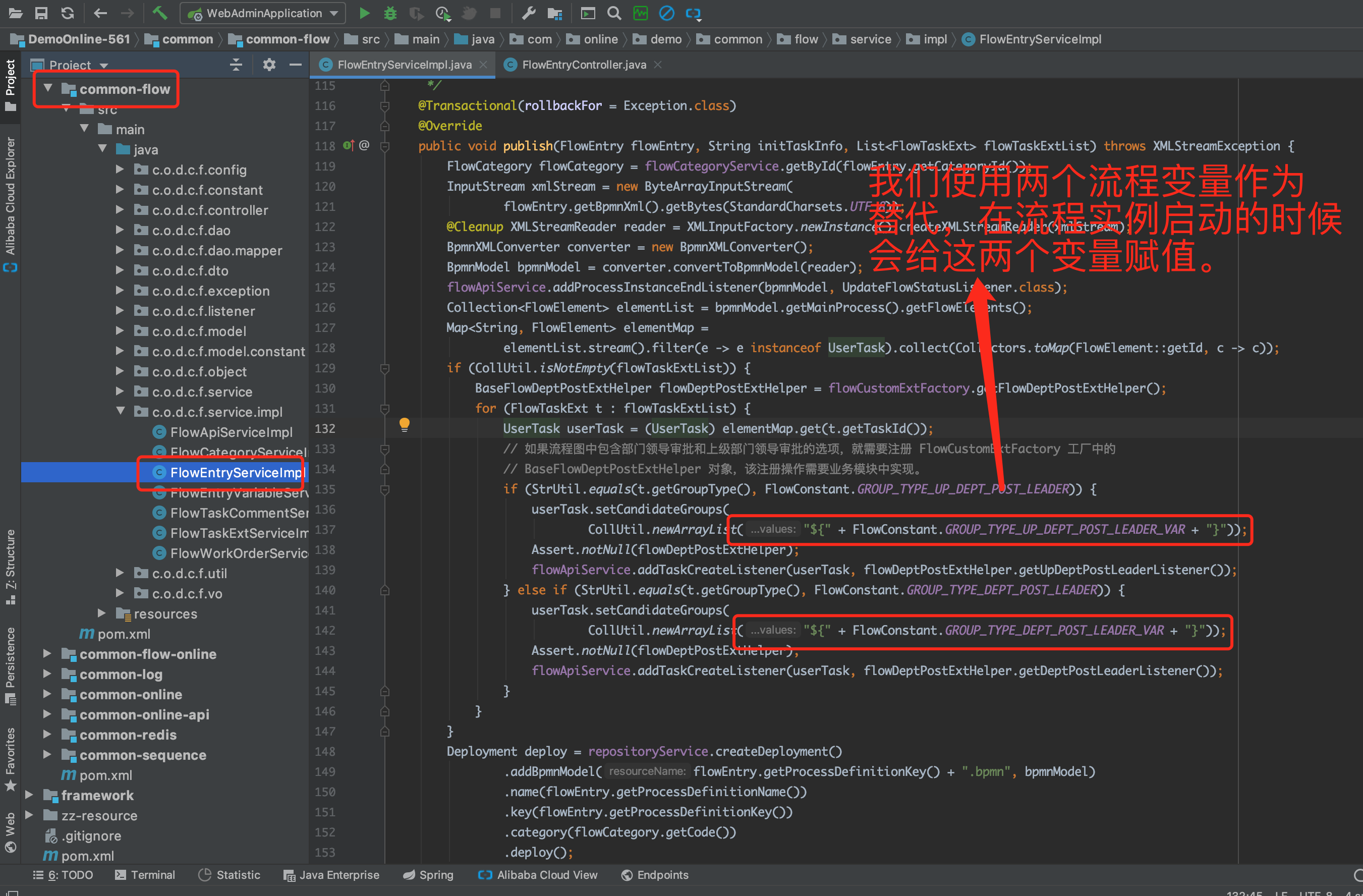
- 在流程实例启动的时候,会判断当前流程任务中,是否包含「发起人本部门领导审批」和「发起人上级部门领导审批」的用户任务,如果包含,就会在流程实例启动的时候,根据实例的发起用户,找到该用户的「本部门领导岗位 ID」和「上级部门领导岗位 ID」,并赋值给上图中对应的变量。

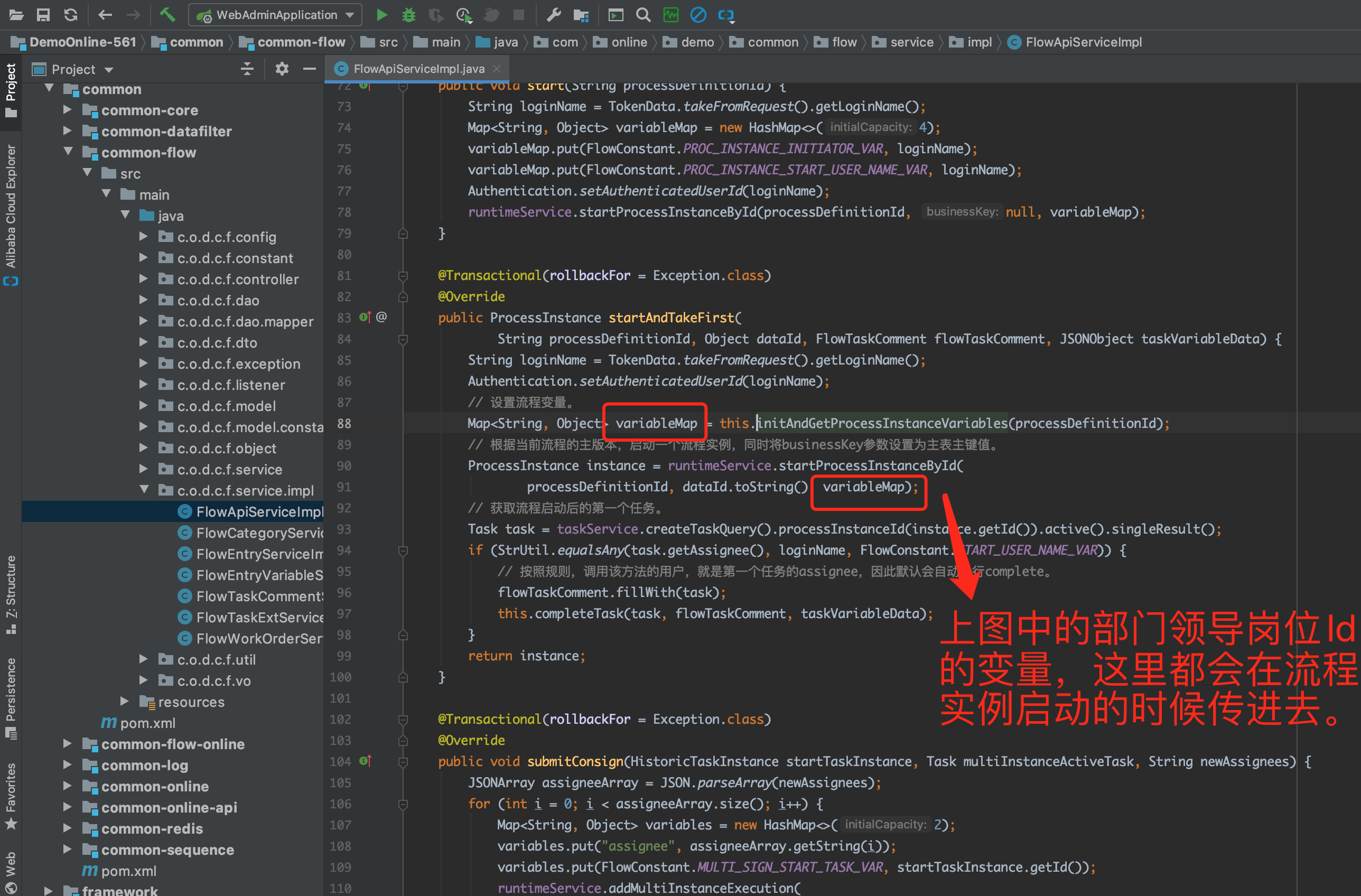
- 流程执行到设定为「发起人本部门领导审批」和「发起人上级部门领导审批」的用户任务时,就会触发流程发布时动态绑定的任务监听器,下面仅以「发起人本部门领导岗位」监听器为例。监听器最最主要的作用是当无法正常获得发起人部门领导岗位 ID 时 (deptPostId == null),监听器会自动把任务的 Assignee 缺省指派给发起人。这里只是缺省行为,也是为了给用户演示如何支持类似的功能。开发者可以根据需求,使用自定义的监听器完成自己所需的需求。

- 前面介绍的是缺省流程,最后讲一下如何扩展缺省行为。
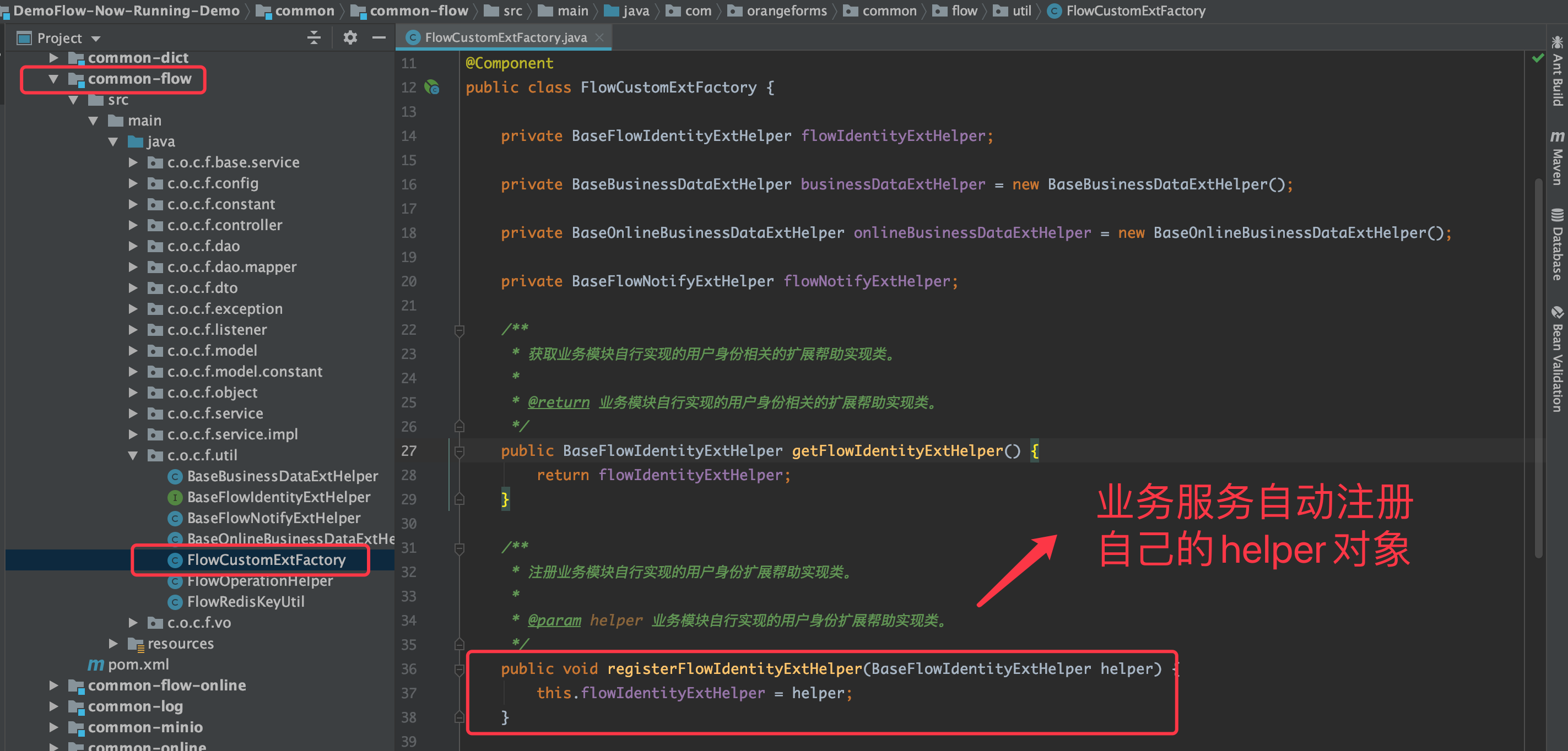
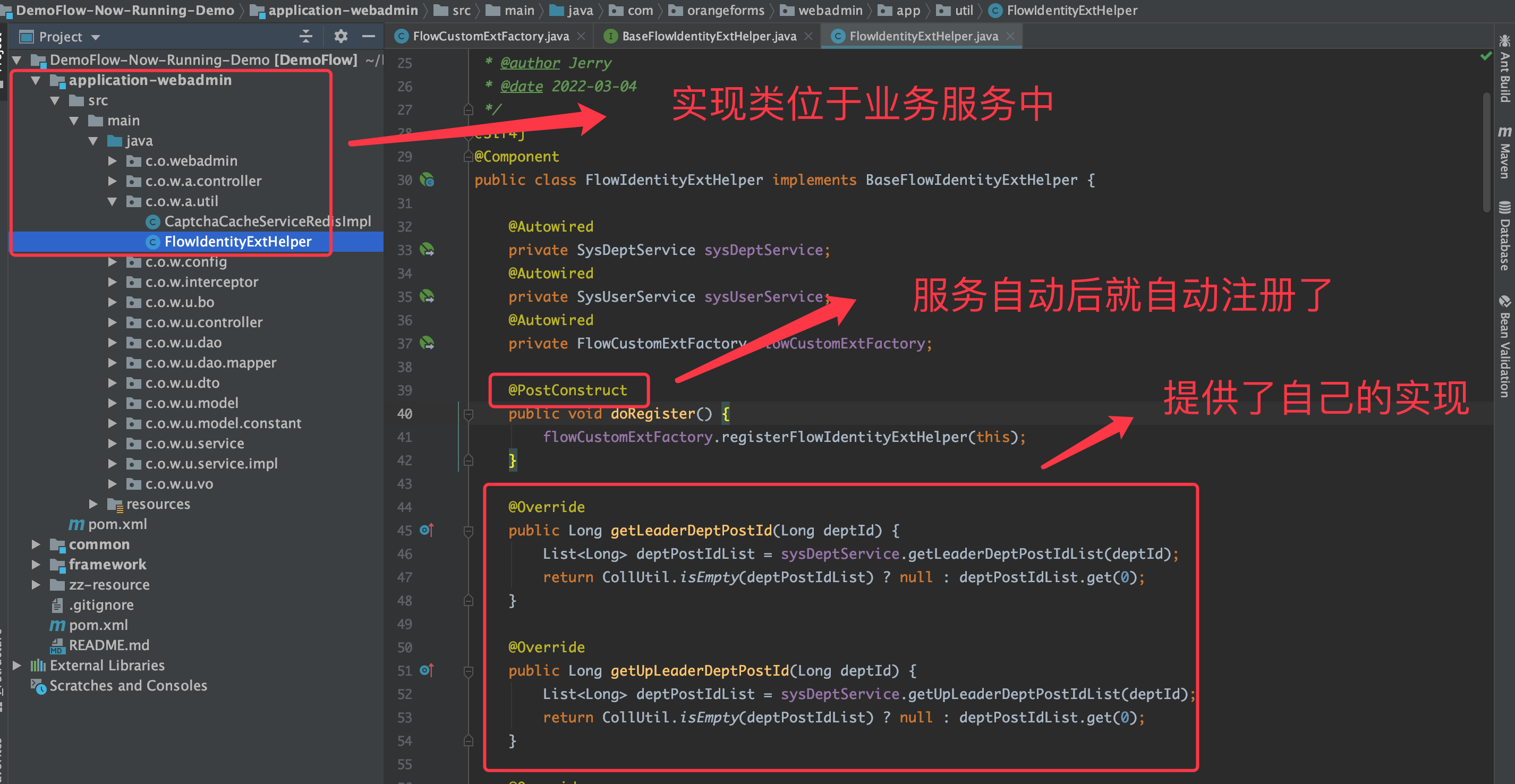
退回设置详解
对应于流程编辑器中的「退回设置」功能,具体见下图。
- 重新审批。假设当前流程任务执行路径为 A -> B -> C,如从 C 退回到 A ,当 A 再次提交审批时,将再次提交给 B 节点。
- 从当前节点审批。假设当前流程任务执行路径为 A -> B -> C,如从 C 退回到 A ,当 A 再次提交审批时,将直接提交给 C,同时将 C 节点的指派人赋值为之前的驳回用户。

- 当退回设置为「从当前节点审批」选项时,可以指定驳回到并行网关内某一具体的节点,驳回后,只有被指定的驳回节点处于待审批状态,而并行网关内的其他节点,不会处于审批状态。当被驳回节点再次提交时,会直接提交到之前驳回的节点。并且将审批人指派人之前的驳回人。

待办任务通知
为待办任务处理人发送新待办任务通知。具体配置和开发步骤如下。
- 为流程配置「通知类型」,配置后所有任务都会发送该类型的待办通知。

- 为指定的任务配置「通知类型」,见下图。如果同时配置了上一步的「流程通知类型」,又配置了「任务通知类型」,那么该任务的通知类型是两者的并集。
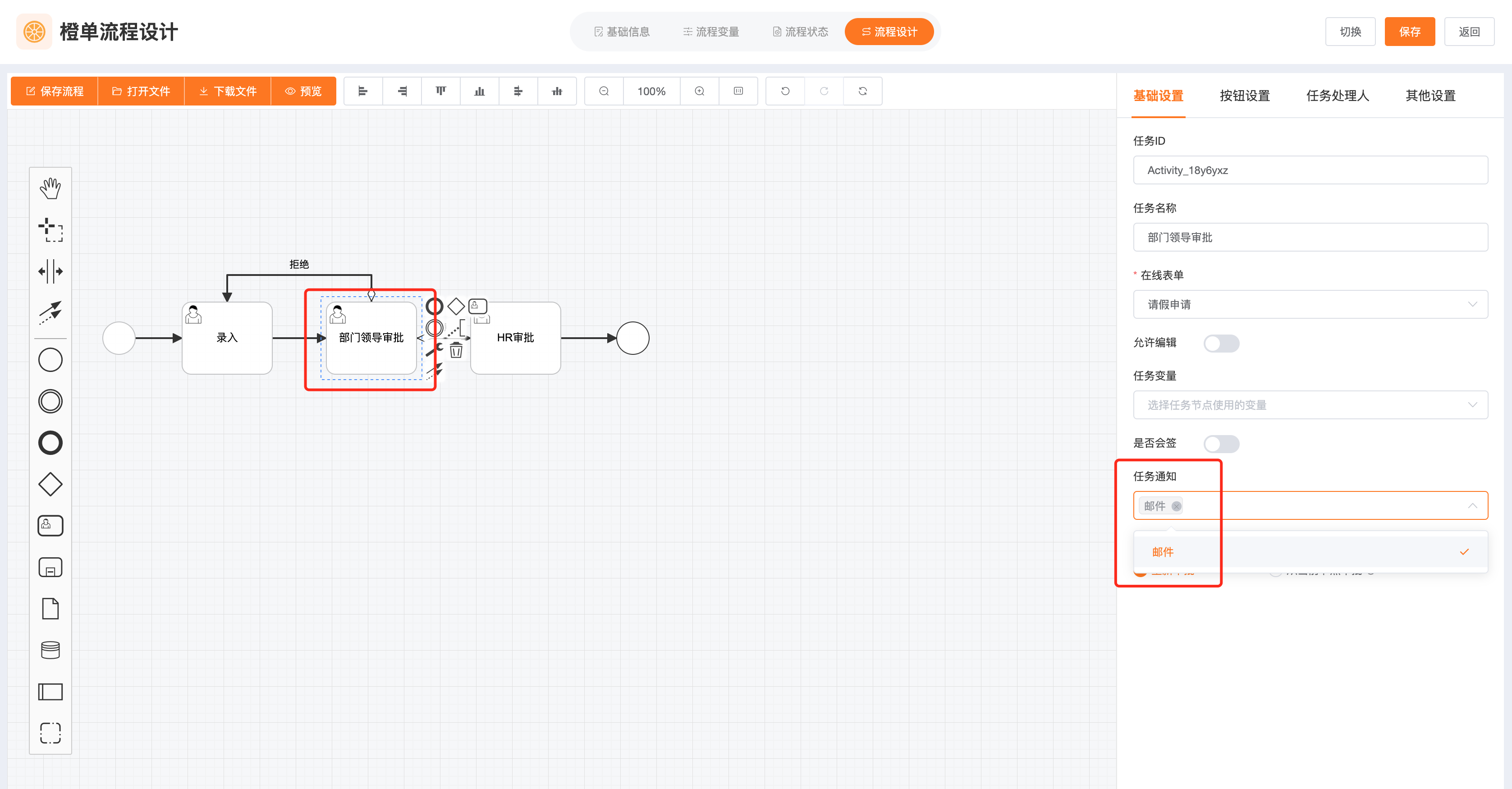
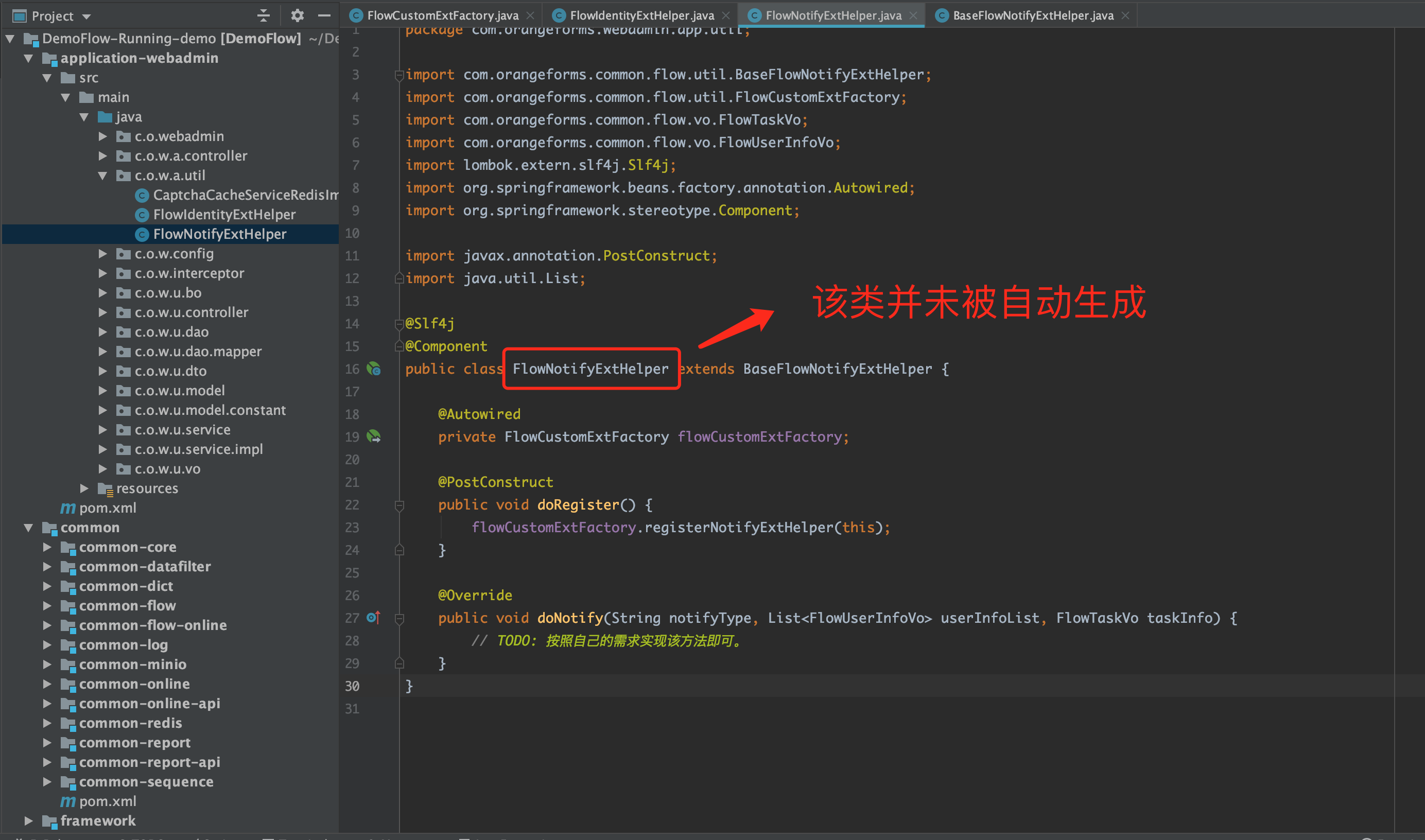
- 在橙单的后端代码中,我们使用「任务监听器」的方式,为待办任务的所有待办人发送指定类型的「通知」。开发者需要根据自己的实际业务需求,实现 BaseFlowNotifyExtHelper 扩展插件类的 doNotify 方法。

- 这里给出 BaseFlowNotifyExtHelper 插件注册的简单示例。
级联删除业务数据
在删除流程数据的时候,可以级联删除与当前流程相关的业务数据。
基本配置和操作
- 如下图所示打开「级联删除业务数据」开关,在删除流程实例时,会同步级联删除与流程实例关联的业务主表数据,以及与主表关联的一对一、一对多和多对多等关联从表数据。
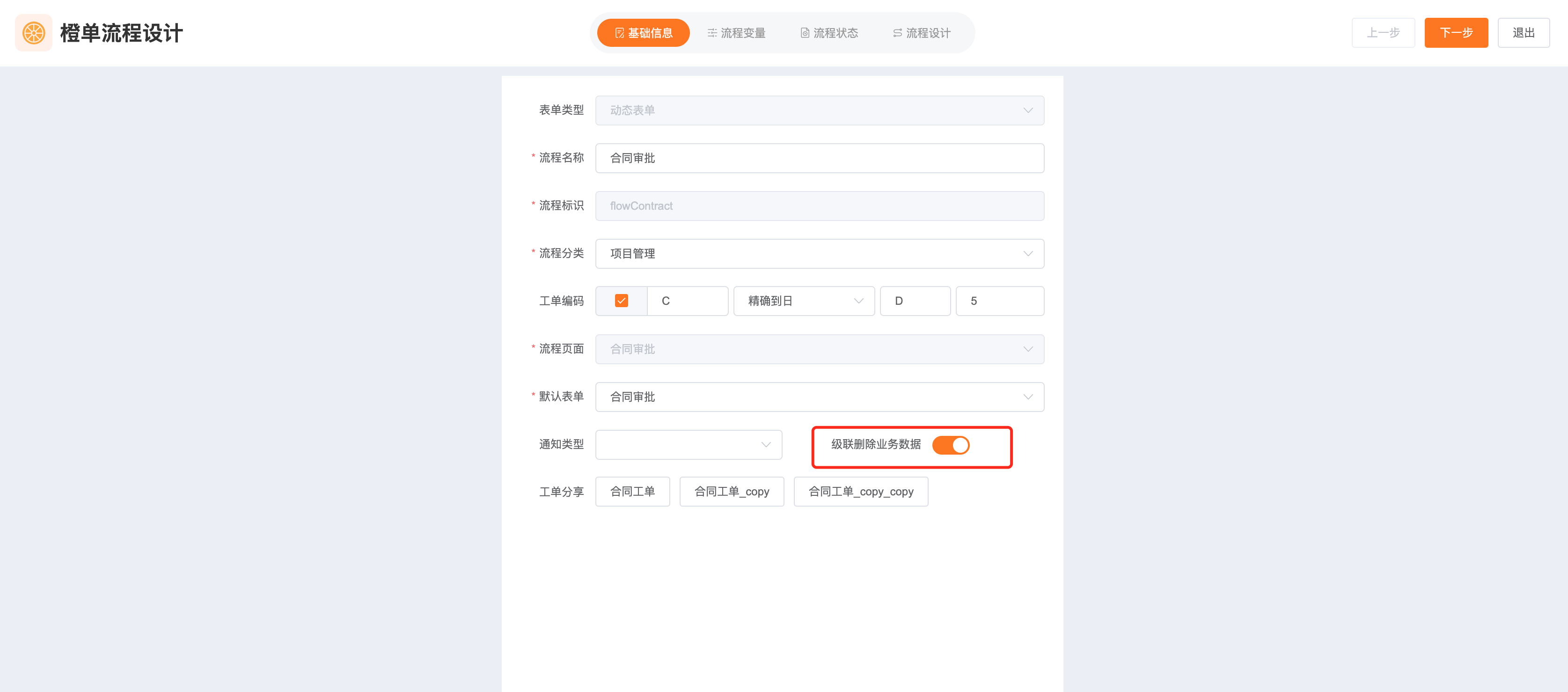
- 删除流程实例,即会同步删除该实例关联的业务主表数据。

在线表单级联删除
- 在线表单中,不仅可以同步删除流程实例关联的业务主表数据,还能进一步级联删除一对一和一对多的关联从表数据。具体配置如下。

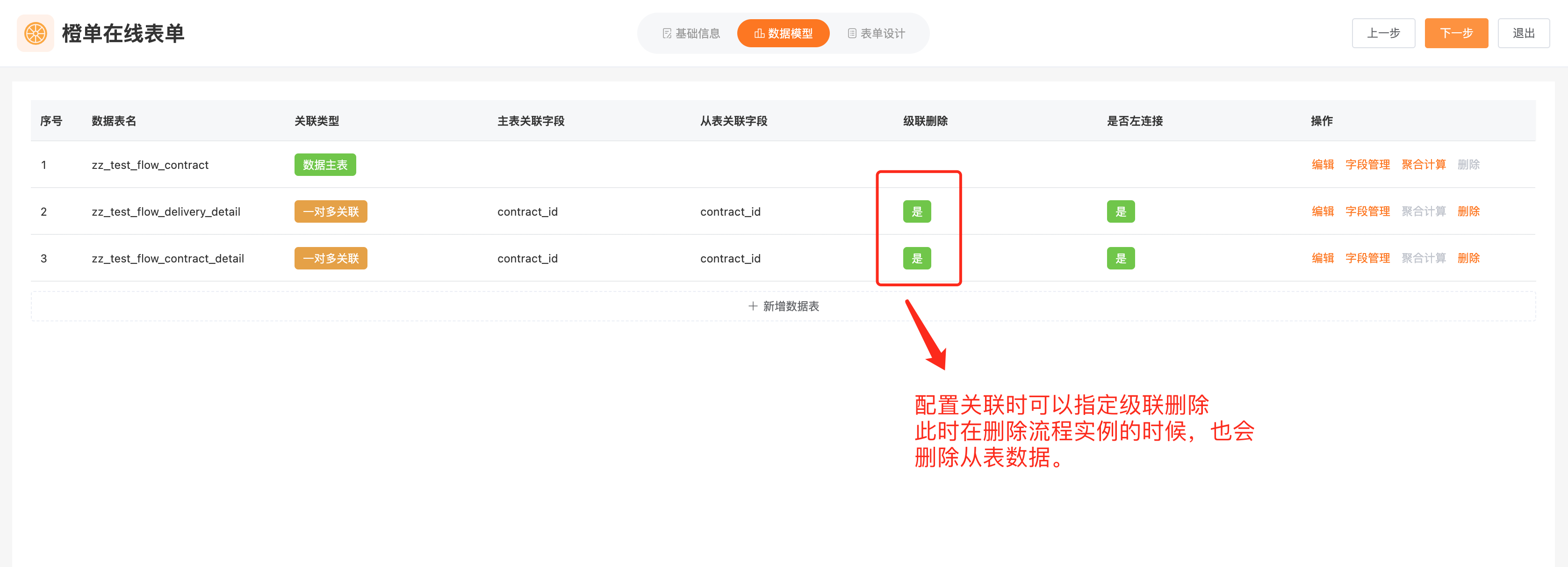
- 在线表单业务表数据的级联删除,是通过在线表单流程模块 (common-flow-onine) 提供的扩展业务服务类 (FlowOnlineBusinessServiceImpl) 来实现的,具体可见该类的 deleteBusinessData 方法。
路由表单级联删除
- 路由表单中,不仅可以同步删除流程实例关联的业务主表数据,还能进一步级联删除一对一、一对多和多对多的关联从表数据。在生成器中的具体配置如下。


- 路由表单业务表数据的级联删除,是通过流程模块 (common-flow) 的流程服务基类 (BaseFlowService) 来实现的,具体可见该类的 removeByWorkOrder 方法。下面是该方法的代码解析说明。
public void removeByWorkOrder(FlowWorkOrder workOrder) {
Serializable id = this.convertToKeyValue(workOrder.getBusinessKey());
M data = this.getById(id);
if (data == null) {
String msg = StrFormatter.format(
"WorkOrderId [{}] don't find business data by key [{}] while calling [removeByWorkOrder].",
workOrder.getWorkOrderId(), workOrder.getBusinessKey());
log.warn(msg);
return;
}
// 级联删除业务数据,调用的是橙单默认生成的remove方法,参数类型为主键类型,如Long、String等。
// 进一步补充说明,橙单默认生成的remove方法,会根据在生成器中的配置,生成关联从表数据的级联删除代码。
this.remove((K) id);
}在线表单状态数据同步
在流程执行结束后,需要将流程的执行状态数据同步到业务表中,以便于业务数据的查询和统计分析。
- 在「在线表单」的「表单管理」菜单,编辑流程使用的在线表单。
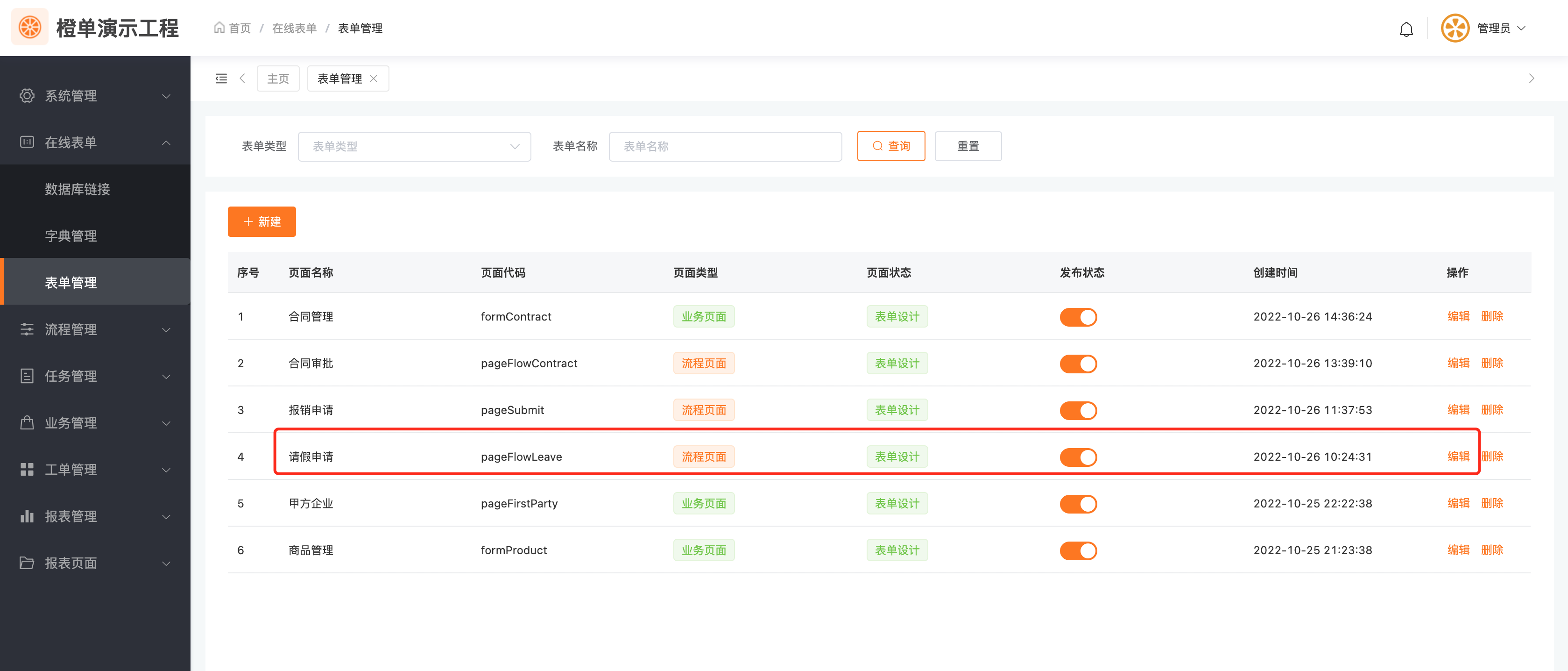
- 选择包含「流程状态」的业务表,然后点击「字段管理」进行字段编辑页面。

- 在左侧选中指定字段,再将其字段类别设置为「流程状态」。

- 在内置的流程结束监听器 FlowFlinshedListener 中,如果是在线表单工作流,就会调用指定的方法,更新上图设置的字段。

- 在 common-flow-online 模块的 FlowOnlineBusinessServiceImpl 实现类中,会根据在线表单中的配置,找到业务表中字段类别是「流程状态」的字段,为其赋值最新的流程状态。
路由表单状态数据同步
在流程执行结束后,需要将流程的执行状态数据同步到业务表中,以便于业务数据的查询和统计分析。
- 在橙单生成器中,为流程依赖的业务主表设置「流程状态」和「流程审批状态」字段。
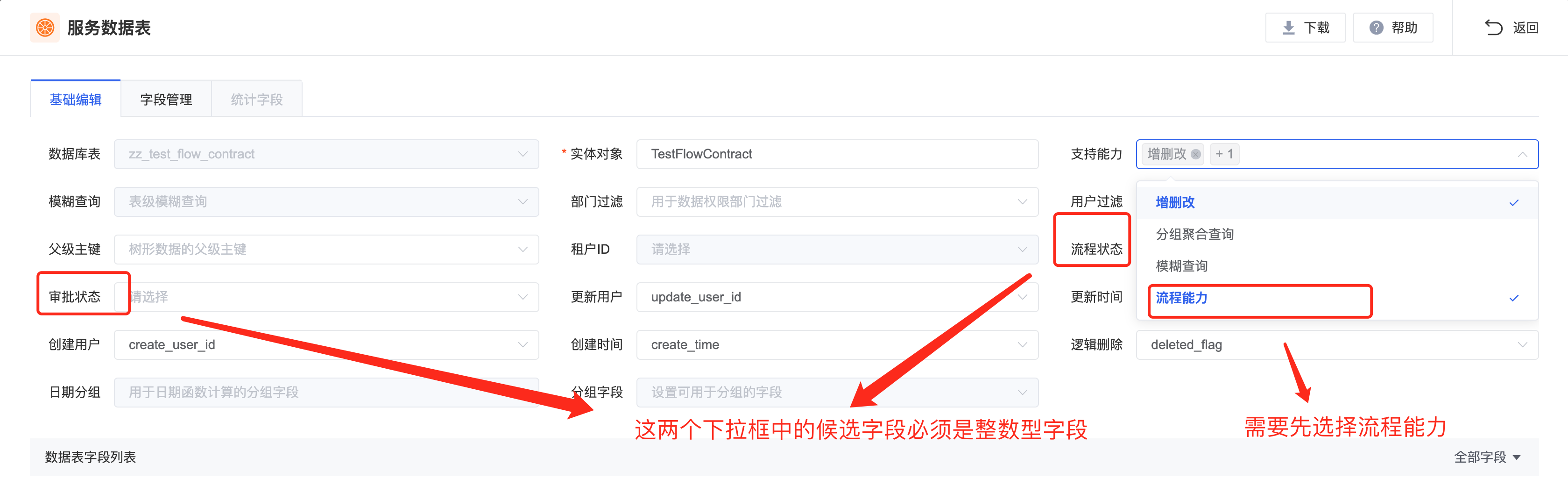
- 在生成后的代码中,会为上一步配置的实体类字段,添加 @FlowStatusColumn 和 @FlowApprovalStatusColumn 注解。
@Data
@TableName(value = "zz_test_flow_leave")
public class TestFlowLeave {
// 主键Id。
@TableId(value = "id")
private Long id;
// ... ... 中间忽略部分字段定义。
// 流程状态。
@FlowStatusColumn
@TableField(value = "flow_status")
private Integer flowStatus;
}- 在内置的流程结束监听器 FlowFlinshedListener 中,如果是路由表单工作流,就会调用指定的方法,更新上图设置的字段。

- 路由表单工作流的状态更新逻辑,在 BaseFlowService 类的 updateFlowStatus 方法中提供了默认实现。
路由表单业务数据同步
为了避免审批中的数据污染最终业务表数据,我们可以分表存储审批中和审批通过完成后的数据,待审批流程以「审批通过」状态结束后,再将审批中业务表的数据,同步到最终的业务表中。
- 在生成器中配置路由表单工作流的时候,可以打开下图所示的开关,即可生成相关的代码。
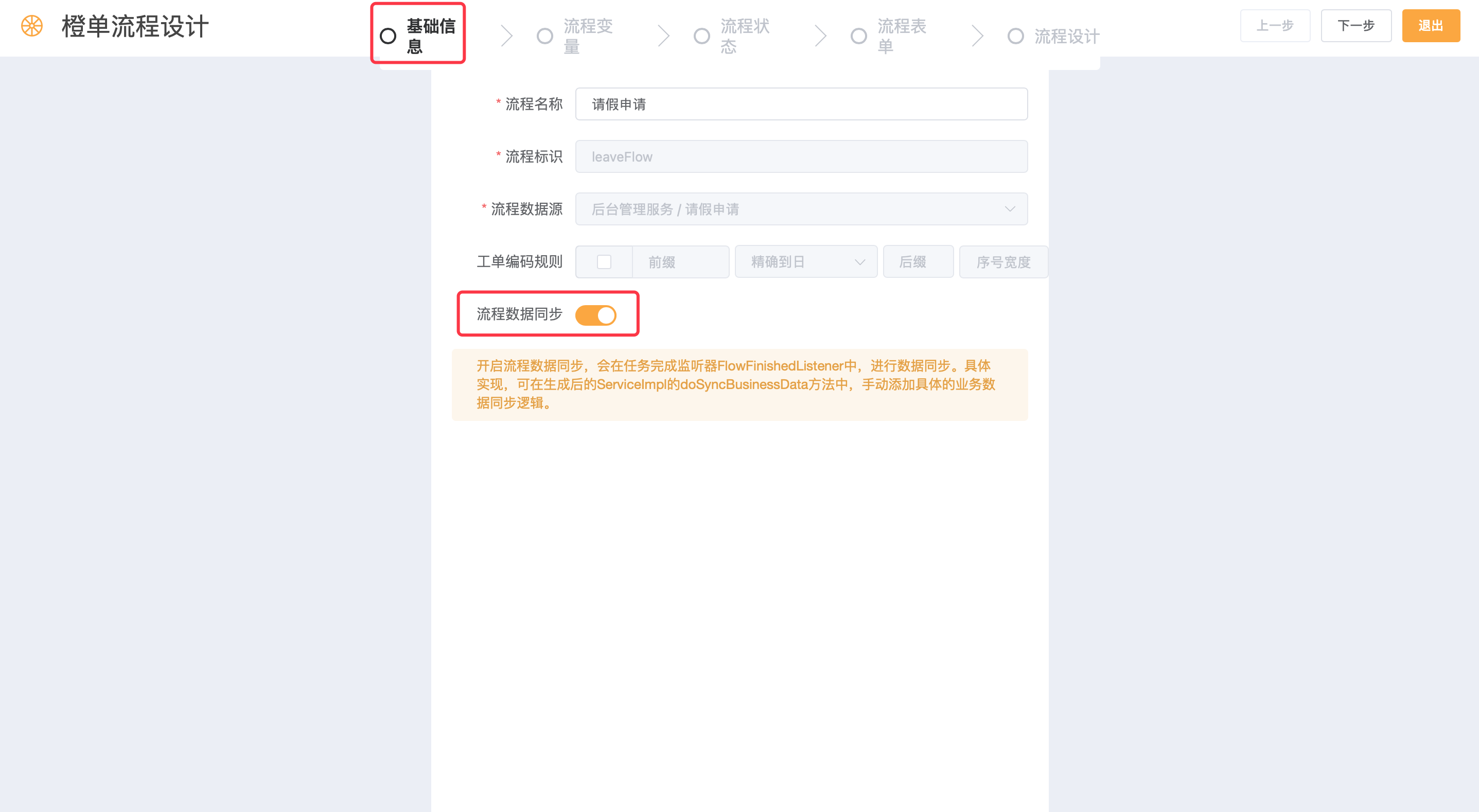
- 下图是生成后工程中,内置的流程结束监听器 FlowFlinshedListener 的代码。红框圈住的逻辑会先判断流程是否是正常状态下结束的,而不是强制终止和撤销操作导致的流程结束。只有正常的流程结束,才会调用业务数据同步的方法。

- 在业务数据扩展类中 BaseBusinessDataExtHelper,提供了业务服务注册 doRegister 方法,流程的业务服务实现类,会在系统启动时将 this 和关联的「流程定义标识」一起注册到扩展插件中。而当流程结束后进行数据同步时,就会根据工单对象中的「流程定义标识字段 (processDefinitionKey)」,查找已注册的流程服务实现类,之后就会调用该服务实现类的 syncBusinessData 方法执行数据同步,syncBusinessData 方法需要每个路由表单工作流的服务实现类自行实现。
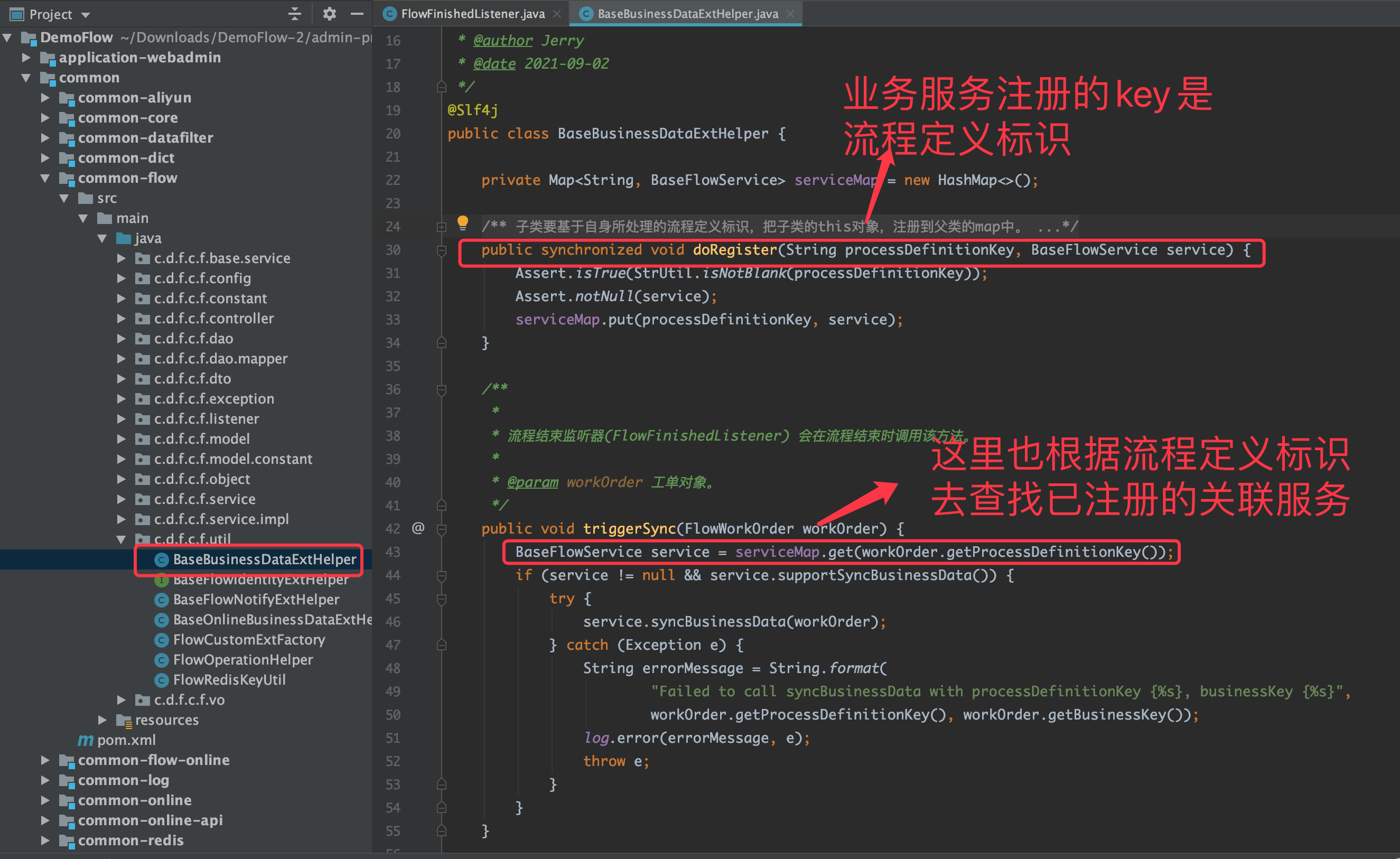
- 在业务服务中,我们会根据配置生成路由表单工作流所需的全部代码。自动生成的流程业务服务实现类,必须继承自 BaseFlowService。并在 Bean 初始化时,将 this 和在生成器中配置的「流程标识」,一起注册到业务数据扩展类 BaseBusinessDataExtHelper 中。

其他问题
本小节主要介绍与流程相关的一些常见问题。
测试环境流程迁移生产
在测试环境中,通常已经配置好了最终的业务流程图,并用于测试。在部署生产环境时,希望只是迁移配置好的流程数据和在线表单配置数据,而忽略测试过程中产生的流程审批数据。具体操作如下。
- 拷贝所有流程引擎 (flowable) 内置的表 (以 act_ 和 flw_ 开头) 数据到生产数据库。
- 清空除「act_ge_property」和「act_id_property」以外,其他流程引擎内置表的数据。
- 拷贝所有橙单流程模块内置表 (以 zz_flow_ 开头) 数据到生产数据库。
- 清空除「zz_flow_entry」、「zz_flow_entry_variable」和「zz_flow_category」以外,其他橙单流程模块内置表的数据。
- 拷贝所有橙单在线表单内置表 (以 zz_online_ 开头) 数据到生产数据库。
- 登录生产环境的业务系统,重新发布所有流程,并同时设置为主版本。
工单编码的计算和补偿
流程工单表 zz_flow_work_order 的 work_order_code 字段值是根据规则配置自动计算而得的。具体可参考 流程管理章节的流程基础信息配置小节。下面我们重点介绍一下在负责规则计算的 Redis 出现异常或人为执行 flushall 命令而导致计数器丢失时,流程工单是如何自动修复并重新执行工单插入操作的。具体实现逻辑可见如下代码及关键性注释。
// 如下代码为FlowWorkOrderServiceImpl类的saveNew方法。
@Transactional(rollbackFor = Exception.class)
@Override
public FlowWorkOrder saveNew(ProcessInstance instance, Object dataId, Long onlineTableId, String tableName) {
// 正常插入流程工单数据。
FlowWorkOrder flowWorkOrder = this.createWith(instance);
flowWorkOrder.setWorkOrderCode(this.generateWorkOrderCode(instance.getProcessDefinitionKey()));
flowWorkOrder.setBusinessKey(dataId.toString());
flowWorkOrder.setOnlineTableId(onlineTableId);
flowWorkOrder.setTableName(tableName);
flowWorkOrder.setFlowStatus(FlowTaskStatus.SUBMITTED);
try {
flowWorkOrderMapper.insert(flowWorkOrder);
} catch (DuplicateKeyException e) {
// 数据插入过程中,如果抛出 “数据重复值 (DuplicationKeyException)” 时,会捕捉该异常。
// 执行 SQL 查询操作,判断本次计算的工单编码是否已经存在。如不存在,该异常则为其他字段值重复所引起,可直接再次抛出。
if (flowWorkOrderMapper.getCountByWorkOrderCode(flowWorkOrder.getWorkOrderCode()) == 0) {
throw e;
}
log.info("WorkOrderCode [{}] exists and recalculate.", flowWorkOrder.getWorkOrderCode());
// 如存在该工单编码的数据,则可以理解为负责计算工单编码的 Redis 出现了问题,
// 需要为该工单字段所关联的 Redis 原子计数器重新设置初始值。
this.recalculateWorkOrderCode(instance.getProcessDefinitionKey());
// 重新初始化后,再次执行generateWorkOrderCode方法计算出新的工单编码。
flowWorkOrder.setWorkOrderCode(this.generateWorkOrderCode(instance.getProcessDefinitionKey()));
// 并再次提交当前的工单数据。
flowWorkOrderMapper.insert(flowWorkOrder);
}
return flowWorkOrder;
}
private void recalculateWorkOrderCode(String processDefinitionKey) {
FlowEntry flowEntry = flowEntryService.getFlowEntryFromCache(processDefinitionKey);
if (StrUtil.isBlank(flowEntry.getEncodedRule())) {
return;
}
// 获取当前流程定义中,为工单编码字段设置的规则配置信息。
ColumnEncodedRule rule = JSON.parseObject(flowEntry.getEncodedRule(), ColumnEncodedRule.class);
if (rule.getIdWidth() == null) {
rule.setIdWidth(10);
}
// 根据当前规则中的数据,计算出该规则在Redis中AtomicLong对象的键。
String prefix = commonRedisUtil.calculateTransIdPrefix(rule.getPrefix(), rule.getPrecisionTo(), rule.getMiddle());
// 根据该键(规则前缀)计算出符合该前缀的工单编码的最大值。
String maxWorkOrderCode = flowWorkOrderMapper.getMaxWorkOrderCodeByPrefix(prefix + "%");
// 移除前缀部分,剩余部分即为计数器的最大值。
String maxValue = StrUtil.removePrefix(maxWorkOrderCode, prefix);
// 用当前的最大值,为该key的AtomicLong对象设置初始值,后面的请求都会在该值上原子性加一了。
commonRedisUtil.initTransId(prefix, Long.valueOf(maxValue));
}结语
赠人玫瑰,手有余香,感谢您的支持和关注,选择橙单,效率乘三,收入翻番。